Surveys
-
1 Provides a comprehensive survey on the applications of MARL. and some of its challenges
-
This includes the following domains and tasks
- Smart Transportation- integrating IoT to increase safety, improve transportation efficiency, and reduce environmental impacts
- Traffic light control, especially in the global traffic network level
- Auto driving, especially with many drivers
- Unmanned Aerial Vehicles
- Cluster Control - controlling UAVs to navigate an environment without hitting each other
- Environment Monitoring - using UAVs to achieve complete coverage while minimizing overlapping FOVs
- Collaborative Transportation - using UAVs for a logistics network and making it operate more efficiently
- Intelligent Information Systems
- Natural Language Processing- includes RLHF and MARL-powered chatbots that can simulate conversations
- Programming Generation - MARL can be used to collaboratively generate, optimize, and test programs
- Recommender systems - MARL can be used to enhance collaborative effort, regulate competing parties, and simulating user preferences.
- Public Health and Intelligent Medical Diagnosis - aims to improve various fields in healthcare including
- Disease prediction, diagnosis, and treatment. MARL is good in this context because it can handle collaborative tasks.
- Medical image processing via an ensemble of MARL agents.
- Smart Manufacturing - using AI to optimize the production process. These methods typically require value decomposition to counteract combinatorial action space explosion.
- Job shop scheduling - involves resource allocation, task management and scheduling, especially in a dynamic environment.
- Industrial robots - focuses on the level of robots that make products. Also focuses on making these robots.
- Preventive maintenance - accounting for machine failure.
- Financial trading - can simulate both collaboration and competition among agents
- Portfolio management - optimize asset allocations and improve returns.
- Trading strategy optimization - especially for more complex financial markets
- Risk Management - MARL systems that can offer decision support, manage prices, test reward formulations
- Network Security
- Intrusion detection - MARL can exploit collaborative and communicative agents to detect complex attacks on dynamic networks
- Resource optimization - MARL agents that manage resources according to changing network demands.
- Smart Education - MARL can offer individualized learning experiences, collaborative learning amongst students, and feedback for the teachers
- Science - general applications in the natural sciences including simulation, discovery, and control.
- Smart Transportation- integrating IoT to increase safety, improve transportation efficiency, and reduce environmental impacts
-
The paper argues that MARL should be assessed based on moral constraints of human society especially considering the limitations of the approach.
-
-
2 gives a survey for multi-robot search and rescue systems.
- Typical agents in SAR include
- UAVs - Unmanned Aerial Vehicles. Typically characterized by cameras as sensors due to their size and weight.
- UGVs - Unmanned Ground Vehicles. Typically characterized with dexterous manipulation capabilities and robust against uneven terrain
- USV - Unmanned Surface Vehicles. They operate on the water’s surface.
- UUV - Unmanned Underwater Vehicle. They operate underwater.
- Interoperability is one challenge in SAR robotics where different types of agents coordinate with each other.
- Common environments for SAR can be divided into three: Maritime, Urban, and Wilderness.
- Common challenges for multi-agent SAR include
- Visual detection especially over vast areas of search or low visibility settings.
- Long distance operation
- Localization / SLAM considering unknown, unstructured environments
- Establishing long-term communication, and transmitting messages over potentially long distances.
- Large search areas.
- Navigation over uneven or unforgiving terrain.
- Some avenues for research include:
- Victim identification, Human condition awareness and triage protocols
- Human-Swarm Interaction and Collaboration
- Multi-Agent Coordination, including task allocation, path planning, area coverage, exploration, and general planning (both in a centralized and decentralized manner)
- Online Learning
- Multi-Objective, Multi-Agent optimization.
- Agent Perception (see Computer Vision).
- Making solutions less computationally heavy.
- Multimodal Information fusion
- Active Perception - agents develop an understanding of “why” it senses, chooses “what” to perceive, and then “how, when and where” (see an analogous system)
- Shared Autonomy
- Closing the gap between simulations and reality.
- Heterogeneous swarms that are
- Interoperable — different kinds of robots can coordinate with each other
- Ad hoc — the types of robots are not predefined
- Situationally aware — agents are aware of the variety of robots being used.
- Typical agents in SAR include
Modeling
- 3 proposes a simulation framework using a small group of representative RL agents for the context of a double auction stock market (agents buy and sell simultaneously)
- The framework runs all agents simultaneously. Also, all agents are heterogeneous.
- The paper provides a framework for analyzing whether or not simulations match real world markets by examining statistical characteristics and market responsiveness.
- Testing is done with three groups of agents — (A) agents that continue training throughout the simulation; (B) - agents pre-trained and are used in the simulation without training ; (C) - untrained agents.
- Continual learning RL agents produce the most realistic market simulation and can adapt to changing market conditions.
- Limitations: Does not address how to calibrate the system.
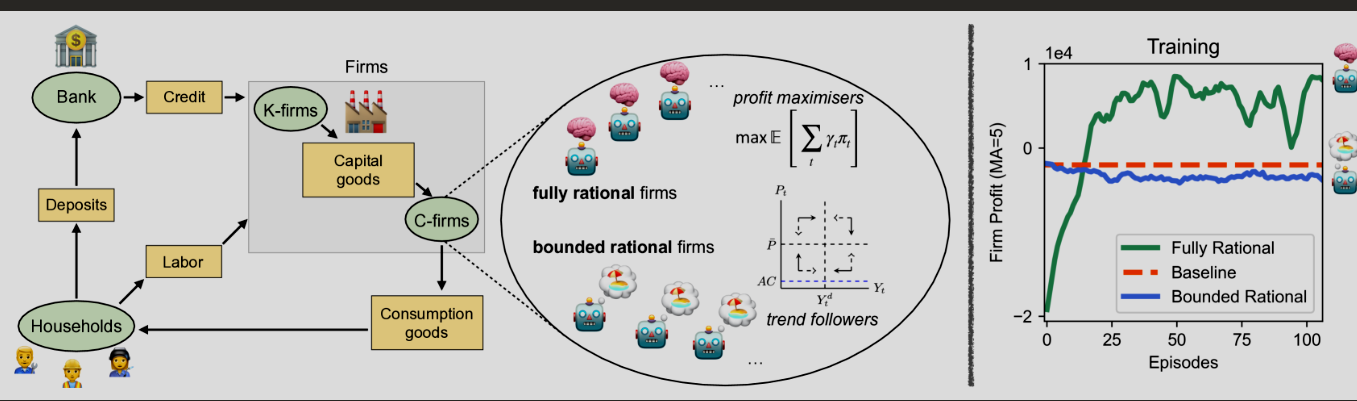
- 4 proposes R-MABM a rational Macroeconomic ABM to study the impact of rationality in the economy.
- Rationale: Traditional ABM models do not account for heterogeneity, bounded rationality or nonequilibrium dynamics. RL can overcome these limitations and at the same time alleviate the burden of designing rules for the agents.
- Like other MABMs, agents (specifically firm agents) have access to price deltas and firm stock values. They then set price and production quantities. The reward is based on agent profit.
- We make use of curriculum learning where we gradually introduce RL agents into the environment.
- RL agents choose and adapt their strategy according to the level of market competition and rationality. They can outperform the profits of bounded rational firms. In particular, RL agents have learn the following strategies in the case of shared policies
- Market Power Strategy - when competition is low, RRL agents learn to charge any desired price on goods sold. They establish monopolies and oligopolies.
- Dumping Strategy - when competition is high, RL agents learn to drop the retail price below market level to undercut the competition.
- Perfect Competition - when competition is high and there are a lot of RL agents, the RL agents learn to set quantities and prices in line with the market.
- RL agents with independent policies outperform RL agents with shared policies since they can adapt to the market and exploit their own niche.
- The impact of rationality is as follows:
- Increased rationality implies higher output.
- Increased rationality implies higher economic stability under conditions where there is perfect competition.
- Perfect competition gives highest output and is most responsive.
- 5 propose an ABM network that is compatible with the use of MARL . The framework encodes the following
- Partial Observability.
- A network model for inter-agent relationships. Connectivity can either be static or stochastic.
- Agent utility functions encapsulated as types.
- Heterogeneous Agent Preferences
- Support for complex turn orders (i.e., turns based on types)
- 6 introduces an ABM model augmented with RL that simulates the Schelling Segregation model.
- Result: High moving expenses promote social segregation despite tolerance to heterogeneous neighbors.
-
7 Applies reinforcement learning in the context of public health — particularly handling pandemics. It aims to optimize lockdown and travel restriction policies and the timing of enacting these policies.
-
Real world country and territory population data was used alongside COVID-19 epidemiological data.
-
Algorithm recommends (unsurprising) strategy of early lockdowns and travel bans and loosening these restrictions later on in the pandemic to balance economic costs.
-
Models the entirety of society as a high level construct due to data limitations.
-
-
8 presents a financial framework for replicating complex market conditions involving two agent types — Liquidity providers and Liquidity takers via MARL.
-
Liquidity Providers continuously quote buy and sell prices at which they are willing to take.
Liquid Takers are the consumers who execute orders.
A third agent — an electronic communication network (ECN) decides which LPs trade with which LT. The ECN exposes prices on both bid and ask sides.
-
LPs maintain an inventory of the quantity traded until an investor accepts the trade.
-
The MARL approach is shared across agent types. The shared policy is studied to gather insights
-
- 9 combines reinforcement learning techniques with ABM techniques to study the dynamics of segregation.
-
Contribution: Combining MARL and ABM to create an artificial environment to observe potential and existing behaviors associated to rules of interactions and rewards.
-
In particular, the rewards each agent receives constitutes the following:
- Segregation reward to promote segregation.
- Interdependence reward to promote interactions among agents of a different kind.
- Vigilance reward to promote the agent staying alive. Added to incentivize the agent to stay alive to collect more rewards.
- Death reward to punish agents who lose to interactions against agents of the opposite kind.
- Occlusion reward to punish agents moving to an area occupied by agents of the same kind.
- Stillness reward to punish agents for staying still.
-
Spatial segregation diminishes as more interdependencies among agents of different kinds are added in the same fashion as if agents are tolerant to one another
-
Older agents tend to be more segregated than younger agents.
-
Policy-Making
- 10 present a MARL approach for Flexible Manufacturing systems that can process multiple product types.
- The paper addresses the problem of scheduling when the environment complexity increases and when product types require distinctive workflows.
- The paper proposes a combination of Game Theoretic and MARL-based approaches
- A Nash game handles the interactions between robots to design collaboration cost functions.
- A MADDPG system determines the actions of each agent.
- The overall action of each agent is dependent on the strategy chosen in the Nash game and by the MADDPG policy.
- 11 proposes a MARL-based approach for Lineless Mobile Assembly Systems.
- The paper addresses the following related problems
- The layout problem (since Mobile Assembly systems have a flexible factory layout). The goal is to determine the layout plan and minimize the cost of rearranging facilities.
- Job shop Scheduling Problem. In particular, the Flexible Job Shop Problem.
- The control approach used is an asynchronous, cooperative, heterogeneous MARL
- The control algorithm determines the placement of stations (coordinates of the station in the environment) and the scheduling of jobs
- The Discrete Event Simulator requests decisions from the RL algorithm.
- The layout planner solves the layout problem by computing the placement of each station per decision step, given the state vector (as encoded by the encoder)
- The scheduling agent solves the flexible job shop problem. The agent computes the next station, process pairing for each job.
- The paper uses Multi agent PPO.
- The paper addresses the following related problems
-
12 proposes using MARL for industrial applications, in particular for flexible job scheduling
- Contribution: Integrating MARL with Deep RL techniques to handle the larger search space via decentralized execution and more parameters. MARL also allows the agents to operate in a cooperative setting.
- It operates on the flexible job shop scheduling task wherein
- Procedure constraint: Each job operation is to be processed in a given order
- Exclusion constraint: Each machine can only process one operation for a job at any time
- Constant constraint: There is a constant set of machines for each operation of jobs.
- A schedule is a valid sequence that assigns operations of jobs to specific machines at the appropriate time slots subject to the above constraints.
- The agent must also perform job routing to satisfy the constant constraint among the set of machines that can perform an operation.
- It makes use of a multi-agent graph with agents as nodes and edges based on the order of machines processing the operations of jobs, and the possible operations of jobs that can be processed. Here, each agent cooperates with their neighbors on the graph.
- The specifications for the environment are as follows:
- The environment consists of a set of machines and a set of jobs in which jobs are routed to specific machines and sequentially processed subject to the constraints of FJSS
- Each machine is associated with an agent for job sequencing — it can select the next job from the machine’s job candidate set to be processed when available.
- Each job is associated with an agent for job routing — it can choose the next machine to process its next operation when the current operation is finished, in which case it is added as a job candidate for the next machine.
- Each job has a workload quantity (indicating how much work per operation); Each machine has a productivity quantity (indicating how much work per step)
- The environment is partially observable
- All actions are triggered only when a machine is available or the job’s current operation is finished at the current time step
- Agents are penalized for taking too long. The goal is to minimize the production time.
- DeepMAG is defined as follows
- A forward pass constitutes the following state
- Update the multi-agent graph
- Update features of each agent.
- For machine-centric features — The feature vector encodes information about the productivity, number of waiting, routed, and executing tasks, current workload quantity of the machine. It also considers aggregates (sums) across each relationship set (see below)
- For job-centric features — The feature vector consists of information about the number of machines related to it, as well as the sum, maximum, and minimum of all workload quantities in jobs that are in a relationship set with it (see below)
- Update the first DQN for job routing.
- Update a second DQN for job sequencing
- The MAG specifies relationships between agents (both machines and jobs)
- Static relationships are between machines in terms of consecutive operations. There are four types of this relationship
- Machine
may send to machine . is a parent of - Machine
may receive jobs from machine . is a child of - Machine
and have a common child. and are couples. They are competitive on the resources of their common children - Machine
and have at least one common parent. and are siblings. They are cooperative on the resources of their common parent.
- Machine
- Executing relationships are between jobs and machines indicating a job is executing at the machine
- Routing relationships are between jobs and machines, indicating the job has just finished their operation and is ready for routing for their next operation
- The routing job set consists of all jobs with a common routing machines. They are competitive on the common routing machine.
- The ancestor set consists of all jobs
with a path to job .
- Waiting relationships are between jobs and machines indicating that the job is in the machine’s waiting queue.
- Static relationships are between machines in terms of consecutive operations. There are four types of this relationship
- Two DQNs are used to reduce cost and enable scalability
- A forward pass constitutes the following state
- The following key results were found
- When compared to methods that simply rely on heuristics, DeepMAG always achieves best performance regardless of the number of jobs.
- The size of the replay buffer should be just right (not too small and not too big to contain outdated data).
- An appropriate number of target network updates is needed (not too few to be too outdated and not too many to be unstable )
- An appropriate number of neurons is necessary (not too few to underfit and not too many to overfit or be too slow to compute)
- Limitations: The paper does not consider a dynamic setting (i.e., when job requirements change).

DeepMAG. Image Taken from Zhang, He, Chan, and Chow (2023) -
13 builds a democratic AI that can design a social mechanism that humans would prefer by majority. It aims for value-aligned policy innovation
-
Rationale: Designing a mechanism that addresses income inequality and prevents free riding is difficult.
-
Contribution: it is possible to harness for value alignment the same democratic tools for achieving consensus that humans use in society. AI can be trained to satisfy a democratic objective
-
A deep RL agent is designed to redistribute funds back to players under both wealth equality and inequality. It, along with other baseline policies, were voted by human players.
-
Policies are represented using the ideological manifold by considering the fractional payout each player receives. It is specified by parameter
which mixes between absolute and relative payouts. - The absolute component combines their contribution with the average from that of other players
- The relative component is determined by the ratio of contribution to endowment.
-
The paper suggests that a simple mechanism (such as this operating in only two dimensions) is perceived as transparent and understandable to humans.
- The agent preserves privacy by operating on the distributions rather than on the individuals themselves. It is slot equivariant.
-
Limitations: A democratic approach is not necessarily the best approach since it might lead to the “tyranny of the majority”. A proposed solution by the paper is to augment the cost function to protect minorities.
-
-
14 Applies reinforcement learning for automated layout, and in particular making use of DDQL in order to layout units for a factory. Presents more as a proof of concept.
-
15 explores an online learning mechanism to learn an equilibrium for resource allocation within exchange economies.
-
Rather than rely on modeling the agents’ utilities, we instead make use of feedback from the environment. The goal is Pareto-efficiency.
-
The problem is defined as follows. Assume we have
agents and divisible resources. We initialize an endowment for each agent . For simplicity and WLOG, assume that for each resource So that the resource space can be denoted
. An allocation
, and denotes the amount of resource allocated to agent . The set of feasible allocations is denoted An agent’s utility
determines the valuation for allocation . We also assume that is non-decreasing since more allocations do not hurt. A price vector
, (to make sure all prices are normalized since only relative prices matter), is defined for the exchange economy. denotes the price for resource . Thus, each agent has a price budget
. The goal of each agent is to maximize the utility under the budget. That is, for the entire system, we find the demand under equilibrium
-
To allocate resources, we set the prices for the resources and have agents maximize utility under this price system.
We seek the Walrasian equilibrium in the context of fair division.
Under fair division, we require the following
- Allocations have sharing incentive —
. Each agent has an incentive to share because doing so may yield greater utility. - Allocations are Pareto Efficient — the utility of one agent can be increased if another agent’s utility decreases. That is, if there is no
where and there exists no where . The set of all that are Pareto Efficient is denoted
- Allocations have sharing incentive —
-
To make the setting not require a priori knowledge of the utilities, we frame the problem further as follows.
Each agent reports feedback for a given time step
where is sub-Gaussian and We optimize two varieties of losses.
- The CE loss
is the difference of the utility between current allocation and the CE equilibrium. Denote - The SI loss is defined with fair allocation in mind, defined as follows
- The CE loss
-
We make additional assumptions. Let
be an increasing function mapping to a feature value; be an increasing function, and be a set of positive parameters. Then we consider utilities in the following class We aim to learn
. We relax these assumptions further for the sake of practical use is continuously differentiable. It is Lipschitz-continuous with constant and , .
-
For the algorithm, we define
-
We can prove the following bounds for the loss under the relaxed conditions above. Both show that learning is done at
rate.
-

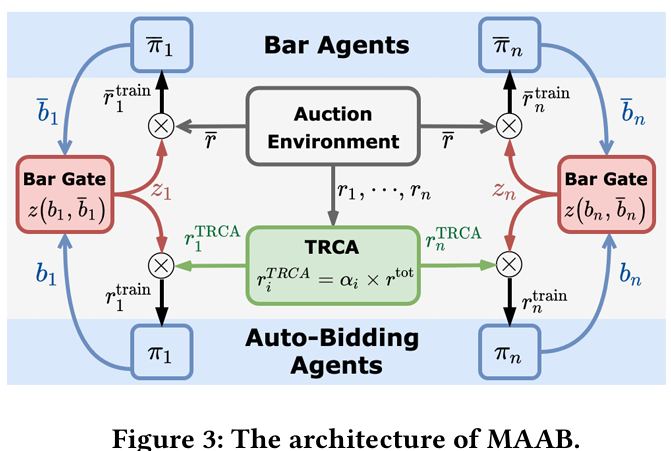
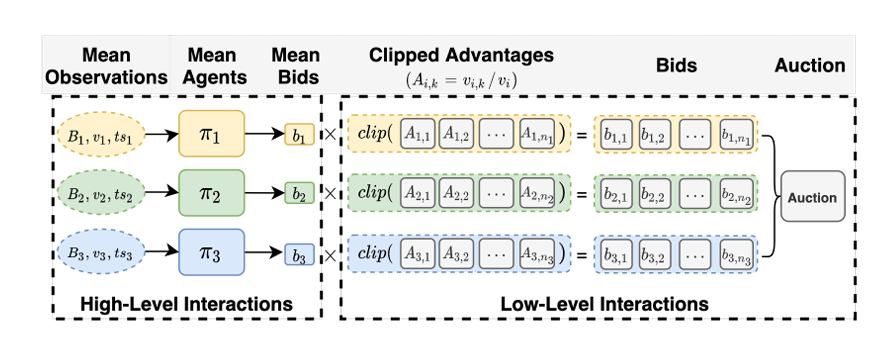
- 16 proposes MARL framework for Auto-Bidding (MAAB) which learns auto-bidding strategies in a multi-agent setting. It also examines the use of a Mean field approach for scale.
-
Motivation: Prior approaches focused only on an Independent-Learning setting where agents ignore the presence of others.
The goal here is to formulate the problem as a cooperative, competitive scenario between individual agents.
-
The problem is as follows. The agents have
impression opportunities and can give a bid on behalf of advertiser at time . The agents play a closed second-price auction , where if agent wins they receive impression value (interpreted as reward) and makes payment . Each agent also has a budget constraint . The goal is
-
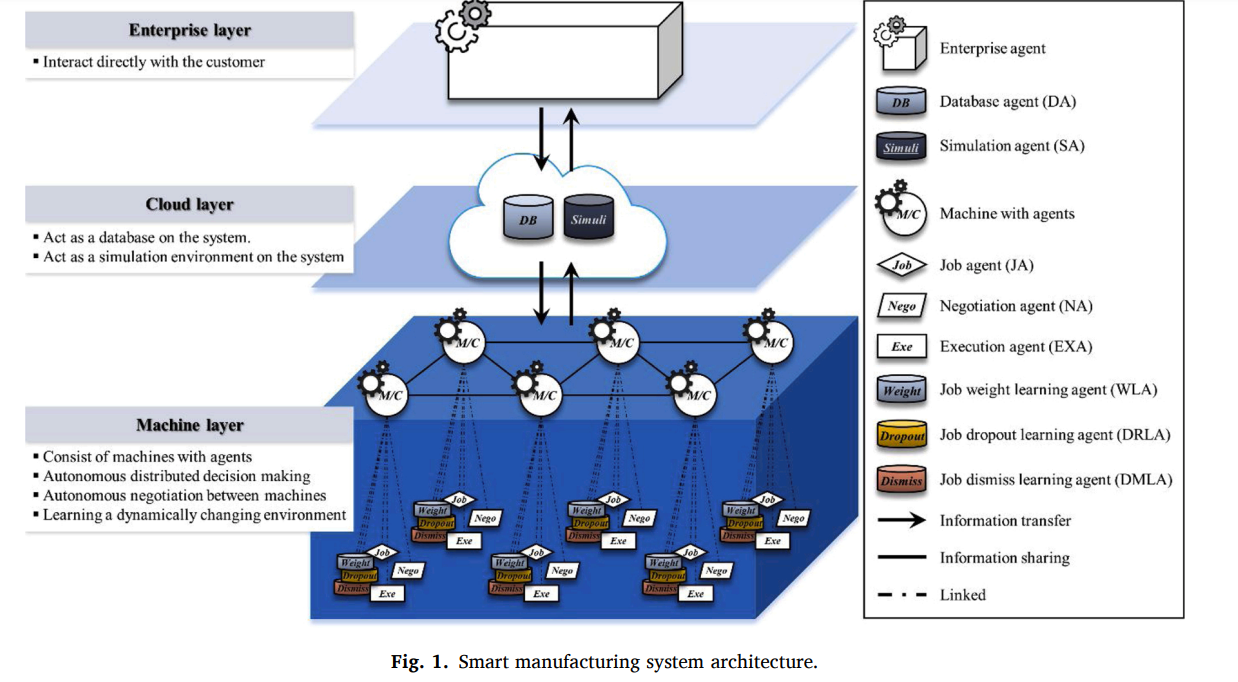
- 17 proposes a flexible smart manufacturing system with distributed intelligence
- Unlike previous work, it aims to decentralize the decision making process for planning and scheduling. It also aims to make RL agents be more adaptive and flexible when responding to a dynamic manufacturing environment.
- Consists of three agents
- The enterprise layer interfaces with the customer directly, receives customer orders and delivers the job schedule information to the customer.
- The cloud layer stores customer order information and production plan and scheduling regarding the agent. It also provides the simulation environment.
- The machine layer is responsible for the decision making between intelligent agents.
- The manufacturing pipeline is as follows
- Job arrives and its information is uploaded. New jobs are produced.
- Job evaluation, scheduling, and prioritization.
- Machines take jobs. If the job can be negotiated for, then machines negotiate between the jobs.
- The goal is to balance between the setup time of having many agents take a job, and the throughput increase of having many agents take the job.
- Job evaluation and negotiation is repeated until all jobs are allocated.
- Use the RL policy to make next decisions
- Execute the production plan
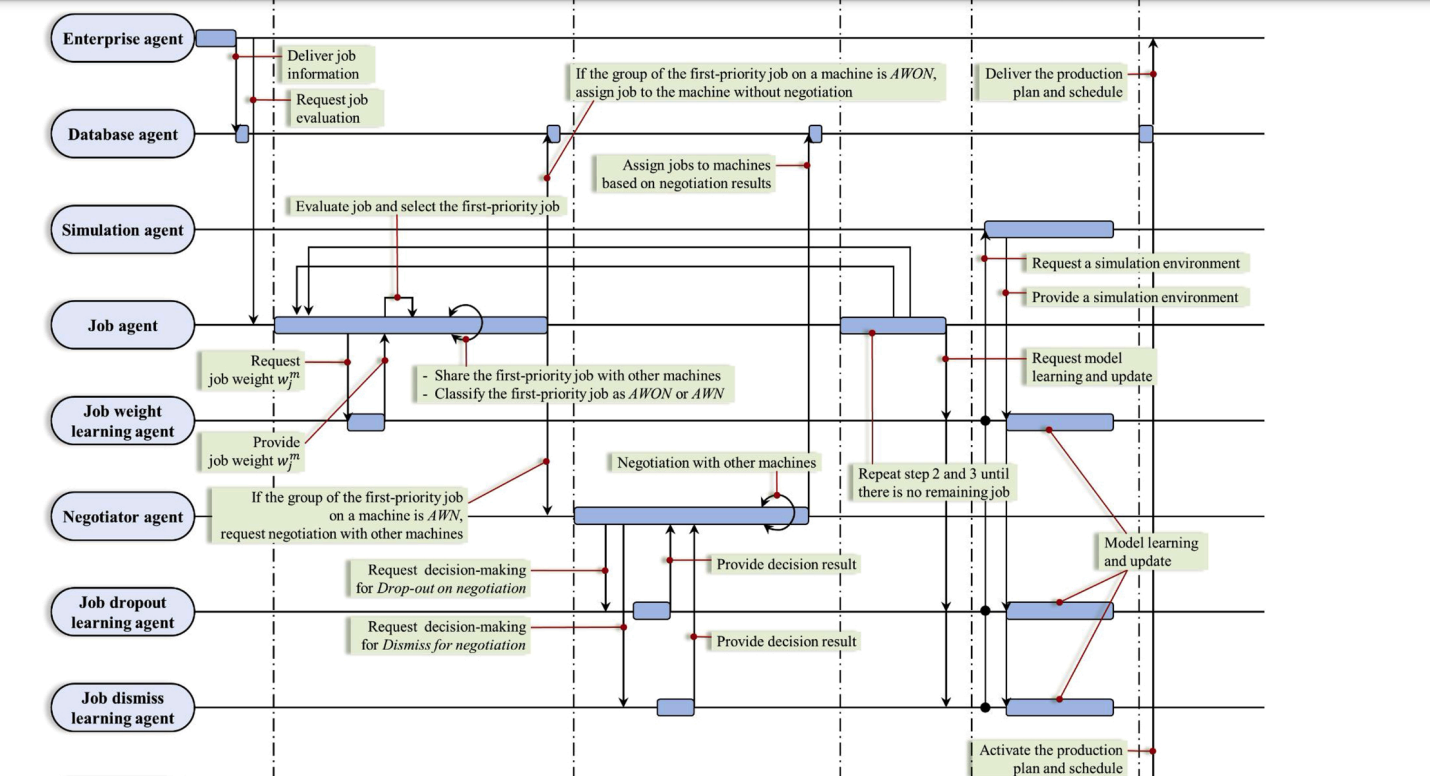
-
18 examines the use of MARL to develop a tax system that promotes and balances equality and productivity. It is effective in simulations with human participants and can be extended to real economies.
- Rationale:
- Economic models are too simplistic and do not capture the complexities of humans.
- Prior methods for mechanism design did not consider agents that learnt how to behave .Agents were assumed to be static.
- It is also hard to test economic policy since it can deal with long time scales.
- Both the workers in the economy and the policy maker are powered by reinforcement learning.
-
In the model, higher skilled workers earn more for building houses. Building houses takes effort which lowers utility.
-
To quantify equality, the Gini Index is used as follows
-
To quantify productivity, the sum of the agent’s wealth is used
-
The policy maker sets the tax rates.
-
- Learning is done via an inner-outer loop. The policy maker has no prior economic knowledge or assumptions on agent’s utility functions.
- The inner loop optimizes the agents. The outer loop optimizes the social planner.
- As is typical of MARL, there is more non-stationarity due to changing strategies.
- Note that both agents and the central planner are trained jointly.
- Agents are first pre-trained on the free market scenario to adapt to the game’s dynamics. Then, a baseline (non AI economist) tax policy is applied.
- It makes use of entropy regularization.

AI Economist Pseudocode. Image taken from Zheng et al. (2020) - Consequences observed
- Specialization comes because workers learn to balance income and effort.
- Agents with lower skill earn income by collecting and selling raw materials
- Agents with higher skill earn income by building products and buying from low skill agents.
- The AI policy maker achieves a better trade-off between equality and productivity than baseline methods.
- Under the AI economist, lower income workers have lower tax burden
- The worker agents learn to game the system by alternating between their types] based from whether they are high skilled or low skilled.
- AI and human behavior differs substantially. Humans display a higher frequency of adversarial behavior
- Specialization comes because workers learn to balance income and effort.
- Limitations
- They do not model the behavioral aspect of economics and the interactions between people
- The simulation is relatively small, operating only on a small gridworld and using only a single quantifier for “skill” without considering additional possible social roles.
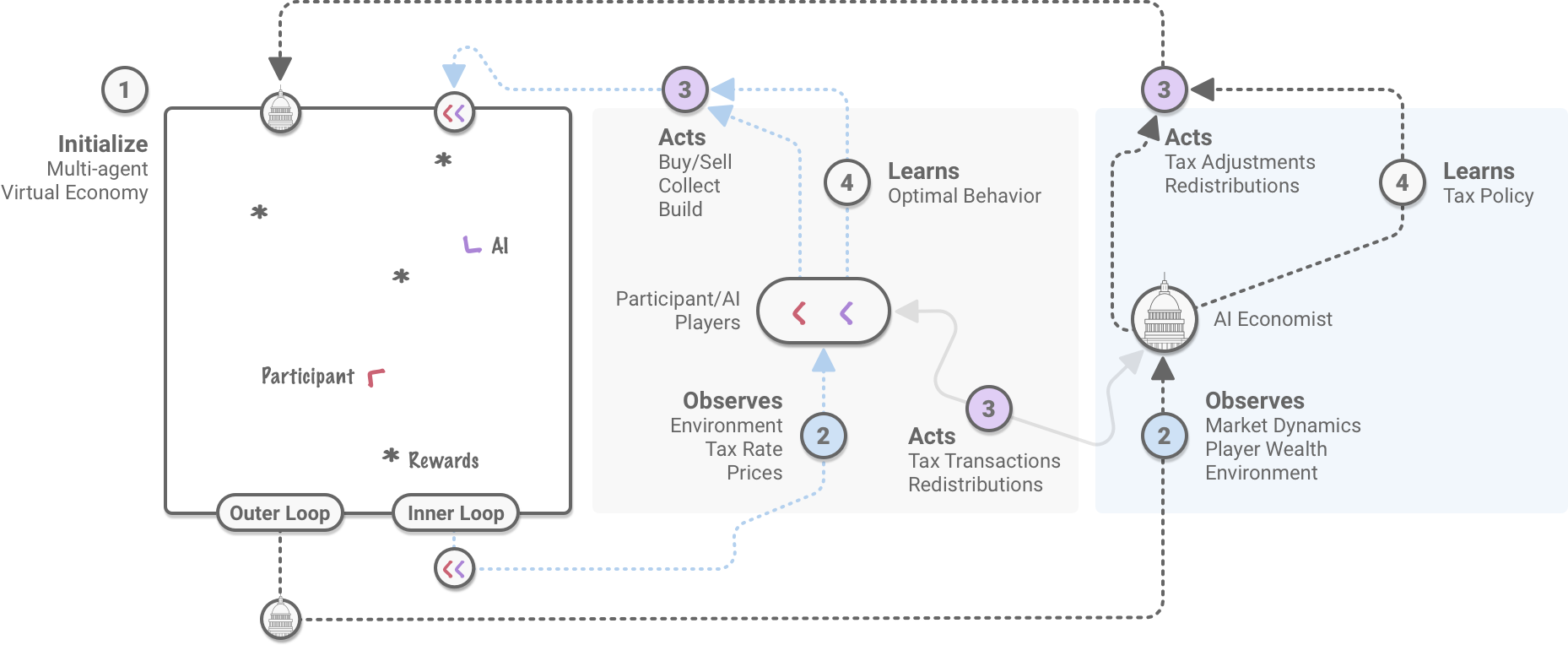
The AI Economist framework. Image taken from https://blog.salesforceairesearch.com/the-ai-economist 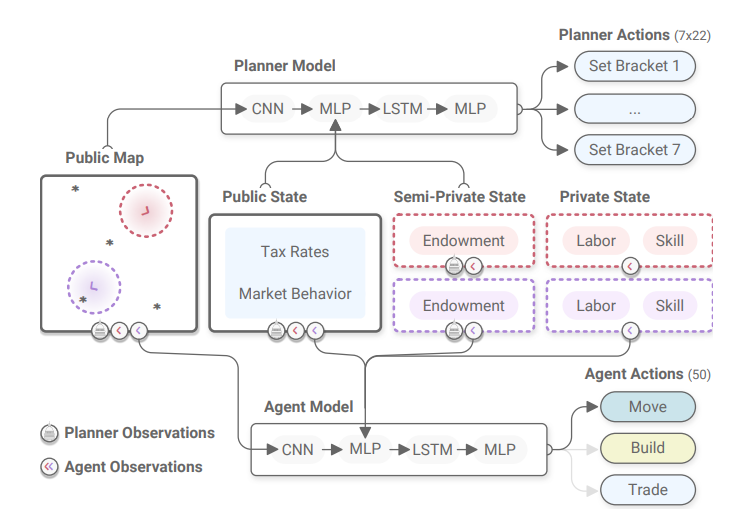
AI Economist Agent Architecture. Image taken from Zheng et al. (2020) - Rationale:
Links
Footnotes
-
Zhou, Liu, and Tang (2023) Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges ↩
-
Queralta et al. (2020) Collaborative Multi-Robot Search and Rescue: Planning, Coordination, Perception, and Active Vision ↩
-
Yao, Li, Thomas, and Florescu (2024) Reinforcement Learning in Agent-Based Market Simulation: Unveiling Realistic Stylized Facts and Behavior ↩
-
Brusatin et al. (2024) Simulating the economic impact of rationality through reinforcement learning and agent-based modelling ↩
-
Ardon et al. (2023) An RL driven multi-agent framework to model complex systems ↩
-
Li (2022) The impact of moving expenses on social segregation: a simulation with RL and ABM ↩
-
Kwak, Ling, and Hui (2021): Deep reinforcement learning approaches for global public health strategies for COVID-19 pandemic ↩
-
Ardon et al. (2021) Towards a fully RL-based Market Simulator ↩
-
Sert, Bar-Yam, and Morales (2020). Segregation dynamics with reinforcement learning and agent based modeling ↩
-
Waseem and Chang (2024) From Nash Q-learning to nash-MADDPG: Advancements in multiagent control for multiproduct flexible manufacturing systems ↩
-
Kaven et al. Multi agent reinforcement learning for online layout planning and scheduling in flexible assembly systems ↩
-
Zhang, He, Chan, and Chow (2023) DeepMAG : Deep reinforcement learning with multi-agent graphs for flexible job shop scheduling ↩
-
Koster et al. (2022) Human-centred mechanism design with Democratic AI ↩
-
Klar, Glatt, and Aurich (2021) An implementation of a reinforcement learning based algorithm for factory layout planning ↩
-
Guo et al. (2021) Learning Competitive Equilibria in Exchange Economies with Bandit Feedback ↩ ↩2 ↩3
-
Wen et al. (2021) A Cooperative-Competitive Multi-Agent Framework for Auto-bidding in Online Advertising ↩
-
Kim et al. (2020) Multi Agent System and Reinforcement Learning Approach for distributed intelligence in a flexible smart manufacturing system ↩
-
Zheng et al. (2020) The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies . Supplemental blog ↩