- (Algorithm) Self Play - agents use the same learning algorithm or same policy.
- It helps reduce the non-stationarity that would come from having all agents learn using different algorithms .
- (Policy-based) Self-play - Algorithms [^self_play] [^self_play_2] where the agent plays directly against itself to exploit its own weakness.
- These may learn faster than algorithm self-play since the experiences of all agents can be used to train a single policy.
- It is more restricted in requiring agents have symmetrical roles and egocentric observations.
- Self play requires that agents in the game have symmetrical roles and ego-centric observations (i.e., observations are relative to it).
Population Based Training
-
Population-based training - extends self-play by training policies against a distribution of other policies, including past versions of themselves.
-
It allows self-play to be sued in general-sum games with two or more agents, wherein agents may have different (non-symmetric) roles, actions, and observations.
-
The general approach is follows
- Initializel policy population
for each agent . - In the
-th generation, evaluate the current policies with respect to the performance of other policies. - Based on the evaluations of policies, modify the existing policies or add new policies
- Initializel policy population
PSRO
- Policy Space Response Oracles. These involve constructing a meta-game and then applying equilibrium analysis to the meta-game.

-
The meta-game is a simplified abstraction to the original game. This allows a characterization of the types of policies (the population) that are feasible. The set is then refined as training continues.
- The action space of the meta-game
is the set of policies in the current population - The reward for each meta-agent is estimated empirically by simulating policies sampled from the population. In the limit, this will converge to the expected reward of the agent.
- The action space of the meta-game
-
The metagame is then solved using a meta-solver.
- The meta-solver computes distributions
for each population where is the probability assigned to . - This is analogous to mixing policies. It determines the probability that an agent will play a certain policy.
- The meta-solver computes distributions
-
An oracle computes a new policy to add to each agent’s population. The new policy is a best-response policy with respect to the distribution and it is added to the population for the next generation.
-
PSRO is guaranteed to converge, and when it converges the computed distribution
is guaranteed to be a Nash Equilibrium. Any stochastic policy can be obtained through a mixture of deterministic policies so we can consider only deterministic policies. Assuming the episodes terminate, we only have finitely many deterministic policies . -
PSRO may converge to different solution types using different meta-solvers and oracles.
AlphaStar
- 1 Builds on top of PSRO. It achieved good performance in Starcraft II.
- Each observation contains an overview map of the environment and all entities in the environment (with their associated attributes).
- Actions are hierarchical specifying the action type, the unit to perform that action, the target of the action, and when the agent wants to select its next action.
- Policies are initialized using Human Play (i.e., Imitation Learning)
- The policies are then trained using A2C. The agent is penalized for deviating from human play.
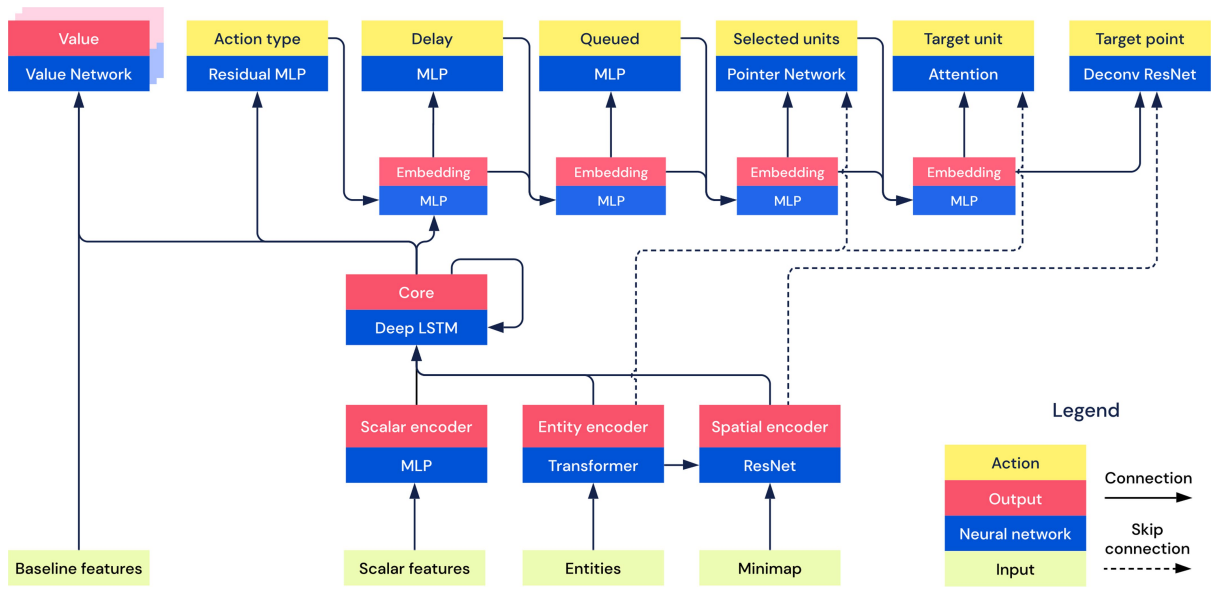
- It makes use of League Training - a single league of policies corresponds to the different types of agents
- It uses past policy copies of each agent type.
- It uses prioritized fictitious self-play (PFSP) to compute distribution
where With a weighting function. - The weighting functions are either hard (to focus on difficult opponents) or variable (focusing on opponents of similar level)
- The weighting functions are either hard (to focus on difficult opponents) or variable (focusing on opponents of similar level)
- There are three types of agents
- Main agents - trained with self-play, PFSP and against past policies of main-exploiters.
- Main exploiter agents - trained to exploit the weakness of the main agent. They are added to the league when they manage to defeat all main agents.
- League exploiter agents - trained against all policies in the league. They are trained to identify strategies that no policy in the league is effective against.
Other Approaches
Fictitious Co-play
-
2 introduces Fictitious Co-Play wherein checkpoints of each agent’s models are saved and an agent partner is trained to collaborate with both the fully trained agents and their past checkpoints.
-
Rationale: Past checkpoints simulate varying skill levels and promotes robustness of the model especially when faced with human collaborators which have their own preferences and skill levels.
-
This allows the agent to better collaborate with humans without having to rely on human data for behavioral cloning.
-
It consists of two stages
- A diverse pool of partners are trained independently in self-play to get a variety of strategies. Checkpoints of each self-play partner is kept.
- An FCP agent is trained as a best response to the pool of diverse partners. The partner agents are frozen so that the FCP agent can adapt to them
-
FCP outperforms previous SOTA methods and is preferred by humans over them.
- FCP is not biased and can adapt to its collaborator’s preferences (assuming choosing either yields equal value).
- FCP can achieve zero-shot collaboration.
-
For larger games, FCP would require a larger population. Methods would need to be explored to encourage behavior diversity.
-
It is reliant on a reward function but this need not be the case.

Links
- Albrecht, Christianos, and Schafer - Ch. 6,9
Footnotes
-
Vinyals et al. (2019) Grandmaster level in StarCraft II using multi-agent reinforcement learning ↩
-
Strouse et al. (2021) Collaborating with Humans without Human Data ↩