-
Agent modeling is the task of learning explicit models of other agents to predict their own actions based on their past chosen actions
-
Rationale: Agents may take off-equilibrium actions for which the policy suggested in something like Joint Action Learning would not prescribe any action.
-
Policy Reconstruction - the goal is to learn models
of the policies of the other agents. - This can be framed as a Supervised Learning problem with the past observed state-action pairs of the modelled agent as input and the output being a new action
. - The agent then selects a best response policy using these models
- This can be framed as a Supervised Learning problem with the past observed state-action pairs of the modelled agent as input and the output being a new action
Classic Approaches
Fictitious Play
-
In fictitious play each agent models the policy of other agents as a stationary probability distribution
estimated from the empirical distribution of agent ’s past actions. -
It is defined for non-repeated games
-
More formally if
be the number of times was selected by agent , then For convenience, we may assume that the initial distribution is a uniform distribution.
-
In each episode, the best response action is chosen given by
-
Fictitious play gives optimal actions; it cannot give a stochastic policy. However, fictitious play can converge to random equilibria.
- If the agents’ actions converge, then the converged actions form a Nash equilibrium
- If in any episode the agents’ actions form a Nash equilibrium, then they will remain in the equilibrium in all subsequent episodes.
- If the empirical distribution of each agent’s actions converges, then the distributions converge to a Nash equilibrium of the game.
- The empirical distributions converge in several game classes, including in two-agent zero-sum games with finite action sets
- For games done repeatedly, the agent will only consider the current interaction
- For repeated games, the action may depend on past history
JAL-AM
- Combines Joint-Action Learning with Agent Modeling
- Here agents learn empirical distributions based on past actions and conditioned on the state
-
denotes the expected return to agent for taking action . 1

- Like AM, it returns best response actions.
- JAL-AM does not require observing the rewards of other agents.
Bayesian Learning
-
Extends Fictitious Play and JAL-AM by incorporating uncertainty and considering a distribution of models rather than a single model. The choice of models is governed by beliefs.
-
The goal is to maximize over beliefs, and in particular, compute the best-response action that maximize the value of information.
-
The value of information evaluates how the outcomes of an action may influence the agent’s belief.
- Rationale: Some actions may reveal more information about the policies of other agents than others .We are effectively using the framework described here.
-
Let
be the space of possible agent models for agent and where each model chooses based on the interaction history . After observing agent
’s action in state , we update using a Bayesian posterior distribution (shown below is the numerator but it needs to be normalized afterward) -
The value of information is then calculated using the following 2
- The agent then selects the action
DNN-based Approaches
- The goal is to learn generalizable models of the policies of other networks using deep neural nets.
- This is applicable especially when we have decentralized execution and where agents only have access to local observation history.
JAL with Deep Agent Models
-
Extends JAL-AM. Here, each agent’s model is a Neural Network
-
The agent model is learnt using the past actions of the other agents and the observation history. This is encapsulated in the following loss function
-
We define the action value as follows. An approximation to make it more tractable is also given using a sample of
joint actions from the models of all other agents. -
Each agent also trains a centralized action value
parameterized by using DQN with the loss function of

- Using the sampling approximation for
may lead to higher variance but also higher exploration with potentially faster convergence.
Policy Reconstruction
-
Rationale: It may not be feasible to use the policies and value functions of the other agents, even with using a model. This is because
- We may be running on decentralized execution
- The policies of the agents may be too complex.
- The policies of the agents change during learning.
-
One common approach is to use Encoder-Decoder Network. We may also use transformers. We have two networks
- The encoder
gives a representation - The decoder gives action probabilities
- The encoder
-
The encoder-decoder networks are jointly trained using cross-entropy loss.
-
Other approaches such as those here can be augmented by conditioning on the learnt representation
.
Extensions
- Recursive Reasoning - an extension of agent modeling where agents consider how other agents might react to their decision making, or how their actions might affect the learning of other agents
- Opponent Shaping - an extension where agents try to shape their opponents — leveraging the fact that other agents are learning and exploiting this objective.
Research
-
3 develops a method to determine the intentions of other agents in the environment and determines whether or not to cooperate or compete, leading to the emergence of social norms.
-
The paper aims to bridge high-level strategic decision making over abstract social goals such as cooperation and competition with low-level planning over realizing these goals.. This is done through hierarchical social planning where learning is done on both levels
-
Low-level learning has two modes — cooperative and competitive High-level learning decides whether to cooperate or compete.
-
Cooperation is achieved through a group utility function
- A high level policy will be conditioned on the joint actions. Low level policies of each agent marginalize out the actions of the other player from the joint policy.
- Policies contain intertwined intentions. Cooperation is built as part of planning.
- Agents interact and after each interaction infer how much they weigh the utility of the other agent. This is akin to a form of virtual bargaining
-
Competition is achieved through maximizing individual utility
- A hierarchy is established with level-
agents best responding to level- agents. Level agents do not consider the existence of other players. - Two mechanisms are implemented — a model-based approach which is standard agent modeling, and a model-free approach for maximizing the agent’s own goals
- A hierarchy is established with level-
-
For higher level strategic learning, planning considers player’s intentions to cooperate or compete.
-
-
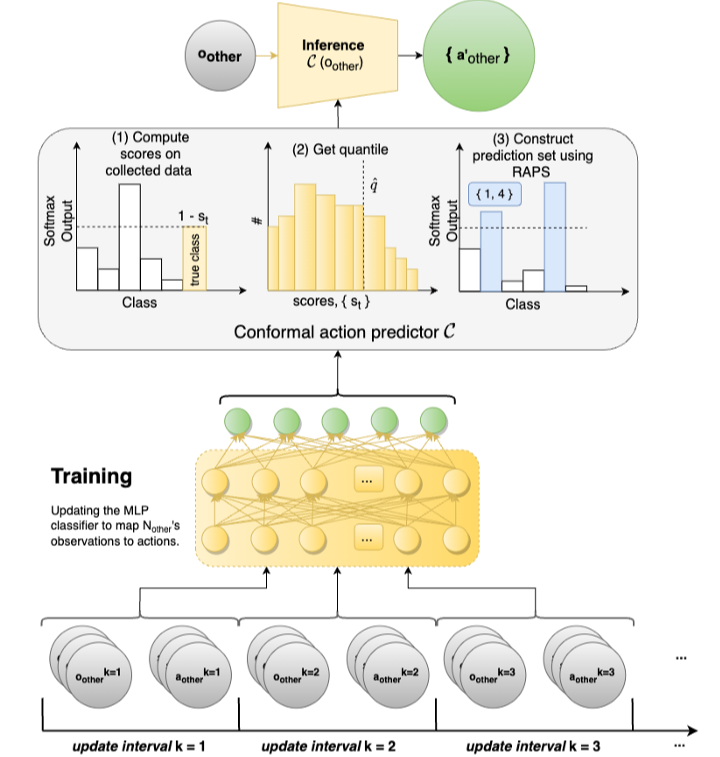
4 proposes CAMMARL, a MARL agent-modeling approach which models the actions of other agents using conformal prediction
-
At each time step, we use a conformal prediction model, defined as
. It takes as input and outputs the conformal action predictive set . -
Let
and be the predicted probability vector for the actions of other agents. Then we can define the total probability mass of the set of actions more probable than And the rank as
Then the predictive action set is estimated as follows
Where
denotes the positive portion of , are regularization hyperparameters and is to allow for randomization and is a tuning parameter for controlling the sizes of the sets. -
Inference using this method favors smaller set sizes which implies the model learns to refine the conformal prediction.
-
Limitation: The model assumes that the state space is accessible globally.
-
Limitation: The results of the paper are based on a simple two-player environment.
-

Links
-
Albrecht, Christianos, and Schafer - Ch 6.3, 9.6
Footnotes
-
This is essentially the best response action except using
instead. ↩ -
In effect, value of information is an extension of the regular state-based value function
↩ -
Weiner et al. (2016) Coordinate to cooperate or compete: Abstract goals and joint intentions in social interaction ↩
-
Gupta, Nath and Kahou (2023) CAMMARL: Conformal Action Modeling in Multi Agent Reinforcement Learning ↩