-
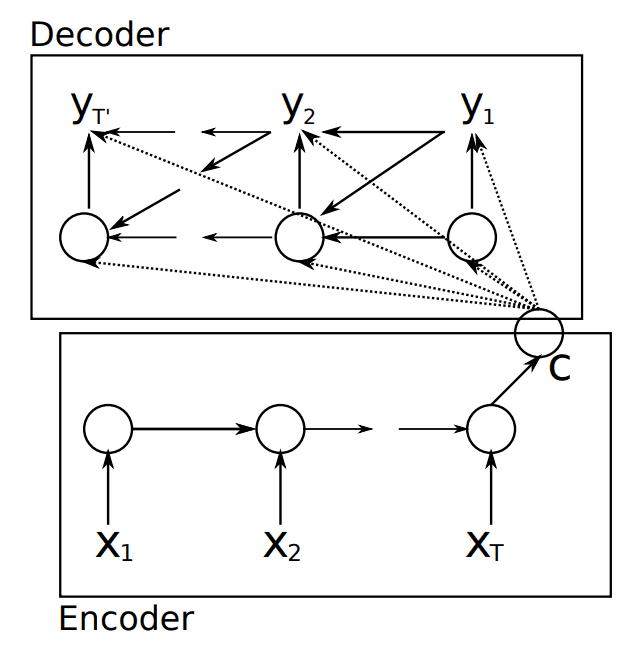
An Encoder-Decoder is a neural network architecture which comprises of two units.
- An encoder takes a variable length sequence as input and encodes it to some hidden state of fixed length
- A decoder which takes the hidden state from the encoder and the leftwards context of the target sequence, and predicts the subsequent token in the target sequence.
-
We may think of the roles of the encoder-decoder as follows:
- The encoder builds a representation of the source text.
- The decoder uses the context from the representation to generate a target text.
-
Encoder-Decoders are useful when the input sequence and output sequence can have different lengths.
-
During inference, we condition the decoder on the tokens already predicted.
-
The encoder transforms the input data as follows.
Suppose our input sequence is
. Then, at time step , we obtain a hidden state as Where we concatenate the input feature vector with the previous hidden state.
After this, we transform the hidden states into a context variable
such that -
Let
be an output sequence. For each time step
, we assign a conditional probability based on the previous inputs and the context variable. That is,
To perform the actual prediction, we simply take:
the previous token’s target. the hidden state from the previous time step , the context variable. We obtain the new hidden state
as Where
is some function that describes the decoder’s transformation. An output layer is then determined using
to figure out the conditional probabilities. Finally, we use softmax to generate our token . In practice, we may continue generating entries using the decoder simply by feeding the shifted sequence to the model again.
Training
- Since we use softmax for the decoder, we use the cross entropy Loss Function. Training is done end to end.
- We perform an additional step during training and mask irrelevant entries with
so that they do not affect the loss (at the current time step). The masking is necessary since we also need to pad the sequence. - During training, we add a sentence separation marker as follows
<source text> <SEP> <target text>
- At training time, the decoder is conditioned on the preceding tokens on the original sequence. This may be achieved using teacher forcing.
Misc Details
- The models for the encoder and decoder can be anything. But common picks for both are either a RNN or a transformer.