-
Artificial Neural Networks are a collection of neurons stacked in layers. Each layer in the ANN performs some transformation on the inputs. This structure can be thought of as a weighted digraph.
- The goal is that each layer extracts certain patterns.
-
The most basic layer is the Fully connected layer in which all inputs from the previous layer are connected to the neurons in the current layer.
Let
be the weight Matrix and the bias vector. The outputs are determined by
- We must introduce a non-linearity within our Fully connected layer before we pass it to the next layer (especially if this is another fully connected layer). Otherwise, we will waste the power of the layered design as our output would be no better than if we had one layer to begin with.
-
The most basic neural network is the Multilayer Perceptron consisting of at least three fully connected layers stacked on top of one another.
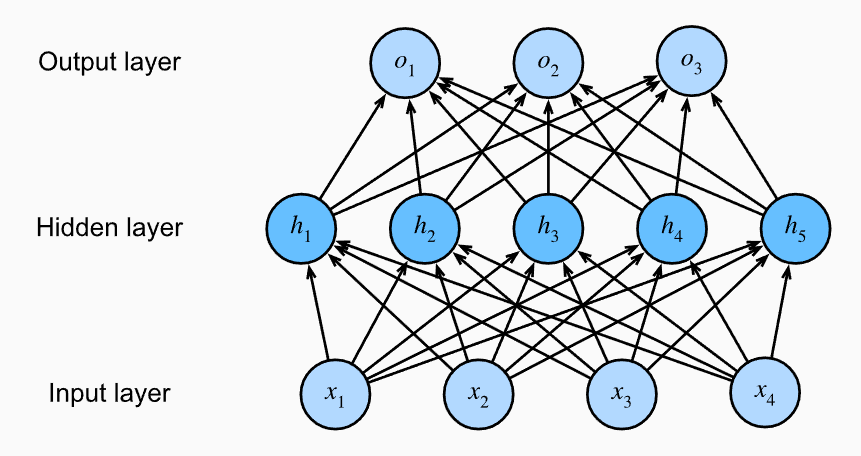
- The computational graph is a digraph which visualizes the dependencies between operators and variables of a function. In the neural network, this gives us a model of the flow of data from input to output
- In the forward pass, we calculate and store the immediate variables and outputs.
Activation Functions
-
An activation function is a function that determines whether or not a neuron will fire based on its outputs.
-
The sigmoid acts as a thresholding function that maps to
). It is defined as - It is a natural choice since it is a smooth differentiable function. However, it is inconvenient because of the vanishing gradient problem.
-
The hyperbolic tangent is a similar function to the sigmoid that maps to
It is defined using . -
The ReLU or Rectified Linear Unit is a function defined as
- This is a popular activation due to its simplicity and performance. The derivative is also simple.
-
The pReLU or parameterized ReLU is defined as
Where
is a parameter. - Its derivative is given by
- This derivative allows us to pass some information through the neuron based on
.
- Its derivative is given by
Backpropagation
-
Backpropagation is the method of calculating the gradient of the parameters in the neural network.
-
Backpropagation involves repeated application of the chain rule.
-
We traverse the network’s computational graph n reverse order from the output layer o the input layer according to the chain rule.
-
We store the partial derivatives required when calculating the gradient of some other parameters.
More formally, let
and for tensors . Now, apply the chain rule to calculate Where
is simply an abstraction to the multiplication operator for the corresponding tensors. We then perform updates via Gradient Descent.
-
-
There is significant memory overhead when it comes to backpropagation since we have to store intermediate values. As such, applying backpropagation to deep networks or to very big batch sizes may give out of memory errors.
Additional Techniques
Dropout
-
Dropout is a regularization technique wherein we inject some noise when computing for each internal layer during forward propagation.
We literally drop out some neuron during training. Because of this, we sometimes remove the dependency of the output of the model with any one neuron.
-
We inject the noise in an unbiased manner so that the expectation of each layer equals the value it would have taken without noise.
Let
be the dropout probability Each intermediate output
is instead replaced by -
The idea of the above is to debias the remaining outputs.
-
We typically disable the dropout during testing.
-
We may also use the dropout to estimate the uncertainty of the prediction on test data. In such a way, using different dropout schemes lets us measure the degree in which the model is confident with its predictions.
Early Stopping
-
Early Stopping is a regularization technique wherein we constrain the number of epochs of training.
-
Let
be a parameter called the patience criteria. Monitor the validation error throughout training. We stop when the validation error has not decreased by more than some amount
for some number of epochs. -
This is motivated by the following reasons:
- Deep Neural Networks are capable of fitting arbitrary labels even when they are assigned correctly, but only after many iterations of training.
- Neural networks tend to fit cleanly labeled data first and only then will it interpolate the mislabeled data
- Whenever a model has fitted the cleanly labeled data but not the randomly labeled examples in the training set, it has in fact, generalized
-
Early stopping allows us to save time while having better generalization.
-
It is less applicable when there is no label noise and each class can truly be separated from each other.
Batch Normalization
Links
-
Zhang et. al - Ch. 3 - 5
-
Differential Calculus - more on gradients and derivatives in general.