- Attention is a mechanism that allows a model to selectively focus on particular tokens within some sequential input.
Motivation
- Motivation: The attention mechanism is motivated by the bottleneck problem found in Encoder Decoder Networks where the encoder must saliently represent the whole source text for the decoder’s use. However, often the decoder only needs portions of the source text.
- This allows the model to learn how to attend to each token in the source text using the tokens so far from the target text.
Query-Key-Value Model
- Another motivation is by observing Databases and retrieval systems where:
- We have a set of keys to index the data found in the database.
- Each key is associated with a value
- The user can retrieve data through queries.
- Such a design leads to the following implications.
- We can design queries that operate on key-value pairs such that they are valid regardless of the database size.
- The same query can receive different answers according to the context of the database.
- The code executed to operate on a large database can be simple.
- There is no need to compress or simplify the database to make the operations effective.
Formal Description
- Attention is a linear combination of the values where the weights are a function of the query and the key. Or more mathematically it is given as follows.
-
Where
, achieved via applying softmax For any differentiable function
. -
Attention can be imagined as doing a proportional retrieval from the database.
-
is used to determine how well the query matches the key.
-
Alignment Scores
-
The following lists choices for
-
Content Base Attention which uses cosine similarity
This is what was introduced in 1
-
Additive (Bahdanau) Attention
Where
is a trainable vector, is a trainable matrix and are the values of and at the -th sentence position -
Multiplicative (Luong) Attention 2
Where
is a trainable. -
The scaled dot product is a simple choice for
where Where
is the dimension of the key-vector. We use this to make sure that exponentiation does not yield values that are too large.
Extensions
-
Attention can be extended to multi-head attention where queries, keys, and values are transformed using multiple attention operations (called heads).
- The idea is that each head attends to different parts of the input.
- By the end of the pipeline, the outputs of all heads are concatenated.
-
Self-attention pertains to an attention mechanism where the tokens are used as the source of the queries, keys, and values.
- In a sense, every token can attend to every other token in the sequence.
- Note that because of this design, the importance of positioning is lost.
-
Attention can be hard or soft
-
Hard Attention involves selecting one part of the input to apply attention to at a time.
This means less calculations in inference time, but is more complicated to train.
-
Soft Attention involves applying attention across the entire input.
This means more calculations in inference time but with ease of training due to differentiability and smoothness.
-
-
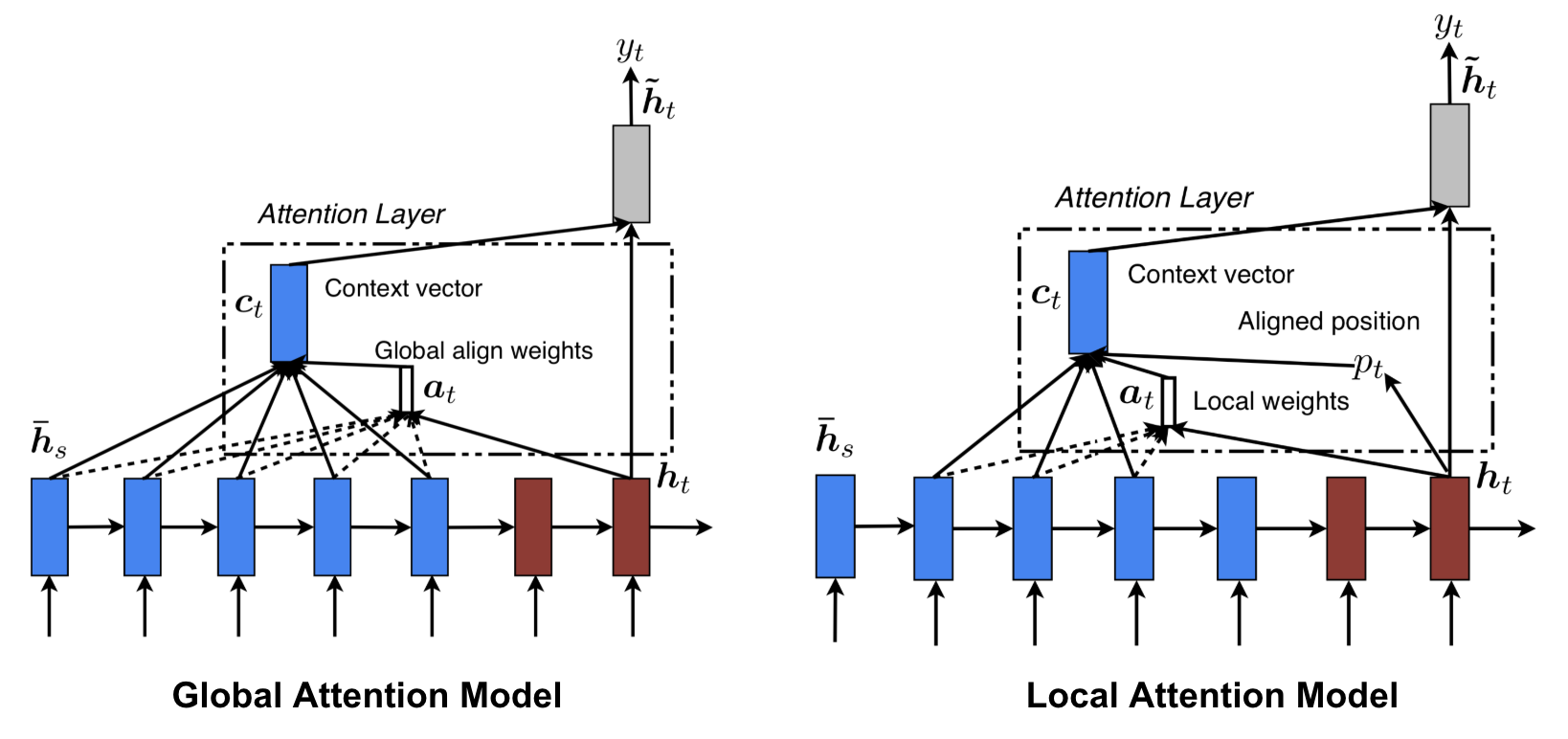
2 proposes a distinction between global and local attention
-
Global Attention means to consider all source tokens.
This can potentially be expensive for longer sequences.
-
Local Attention involves choosing to consider only a subset of the source positions per word.
This involves selecting a small context window around a source token and a predicted position to place this window. We attend to tokens within this window to compute the context vector.
-
Topics
Links
Footnotes
-
Graves, Wayne, Danihelka (2014) Neural Turing Machines ↩
-
Luong, Pham, Manning (2015) Effective Approaches to Attention-based Neural Machine Translation ↩ ↩2