Asynchronous Learning
- The aim is to speed up the process of DQN using asynchronous methods — that is, by running learning in parallel. 1
- Instead of using replay memory, we rely on different threads running different policies and multiple actors perform exploration (via
-greedy policies where is sampled from some distribution) - This reduces training time by exploiting parallelism.
- This allows us to instead use On policy methods with stability guarantees

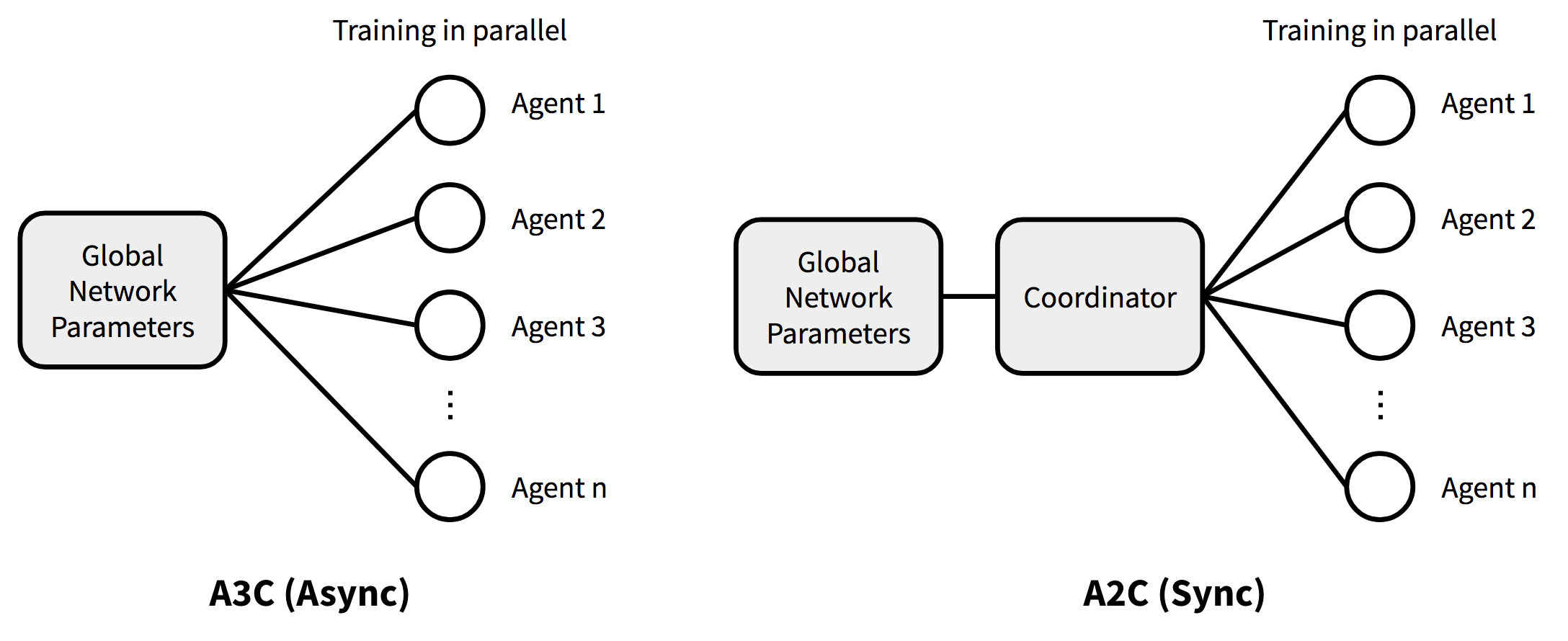
A3C
- Asynchronous Advantage Actor-Critic

-
Here, critics learn the value function while multiple actors are trained in parallel, and accumulated updates are performed for more stable and robust training.
-
In practice ,we share some parameters. between the value function and the policy function.
-
Updates are performed as follows. Here we let
and be the parameterized value and policy respectively and is the estimated advantage function -
We may also add the entropy as a regularization term.
A2C - Advantage Actor-Critic
- A synchronous version of A3C that resolves data inconsistency.
- It introduces a coordinator that waits for all parallel actors to finish their work before updating global parameters. Actors then start from the same policy.
- It can utilize the GPU more efficiently while achieving comparable or better performance to A3C.
ACER
-
Actor Critic With Experience Replay 2. It presents an actor-critic method with stable, sample-efficient experience replay. It is the off-policy counterpart to A3C.
-
It makes use of the
value computed with Retrace, denoted as a target to train the critic by minimizing -
To reduce the high variance of the policy gradient, we truncate the importance weights by a constant plus a correction term. We get the gradient
as As a shorthand
denotes the usual definition of the Importance Sampling ratio using and denotes it on action . The first term in the above clips the gradient and adds a baseline
to reduce variance. The second term makes a correction to achieve an unbiased estimation. -
Finally, it makes use of a modified version of TRPO . Instead of using the KL Divergence, we maintain a running average of past policies and force the updated policy not to deviate from this average to reduce the variance of policy updates.
-
For continuous actor-critic, we make modifications to the estimate
and off policy. We compute a stochastic estimate and a deterministic estimate given by The target then becomes
When estimating
in continuous domains, we use the following truncated importance weights, where is the dimensionality of the action space. -
For trust region updating, we make modify the Retrace estimate by replacing the truncated importance ratio with
.


Footnotes
-
Mnih, et al. (2016) Asynchronous methods for deep reinforcement learning. ↩
-
Wang et al. (2017) Sample Efficient Actor-Critic with Experience Replay ↩