- 1 proposes ALBATROSS (AlphaZero for Learning Bounded-rational Agents and Temperature-based Response Optimization using Simulated Self-Play) for learning both cooperation and competition in simultaneous games.
-
It makes use of opponent modeling where we use a continuous temperature parameter
to estimate opponent skill. The opponent model makes use of the Smooth Best Response Logit Equilibrium. -
The Smooth Best Response is a softmax over the original utilities
. That is -
A joint policy is called a Logit Equilibrium if all agents play the SBR.
-
The SBRLE is the joint policy of the Logit Equilibria of weak agents and the rational agent’s response to the Logit Equilibria.
That is,
, is a Logit Equilibrium policy with temperature .
-
-
Albatross is derived from AlphaZero but fine tuned using Self Play and planning. It learns to approximate the SBRLE
-
Albatross cooperates with rational partners, is robust to weak allies, and can exploit weak adversaries.
-
A proxy model predicts
and The value function approximates the Logit Equilibrium given
and the policy . -
A response model works as follows: For agent
, define the temperature vector of all other agents as . The response model predicts and . The value function is used to approximate a SBR with fixed response temperature
to the action utilities.
-
-
In inference time, the temperature is estimated using Maximum Likelihood Estimation. Let
be the rational agent approximating the temperature , . Given observations of actions and policies for these agents, we have the log likelihood of exhibiting temperature as Optimal play is determined by using the policy of the proxy model with the highest temperature with the maximum likelihood.
-
Limitation: The estimation converges within
timesteps. Shorter games may not benefit from Albatross. -
Limitation: Planning is dependent on the joint action space.
-
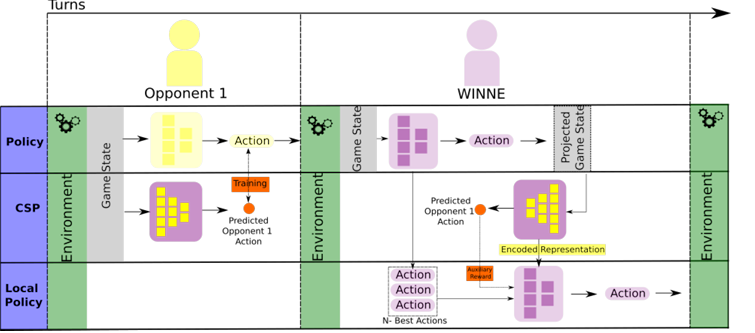
- 2 proposes WINNE, a contrastive learning model for MARL that learns representations for competitive games, as well as model how adversaries might play.
- The model learns how to represent patterns on a game strategy of individual opponents and derives a strategy to play against these strategies.
- The framework is reliant on three requirements
- The model knows how to play the game. This is done using a global policy network that learns a general strategy for the game
- The model knows how the opponent plays the game. This is done using a Contrastive Strategy Prediction network that predicts the opponents actions.
- The model knows how to mitigate any opponent’s actions This is done using a local policy neural network that maps the representation learned by the CSP with a set of best possible actions coming from the global network.
- The balance between generalized and personalized strategy allows WINNE to escape from the catastrophic forgetting problem.
- At the same time, the framework can adapt to its opponent’s strategies
- If the opponent has no strategy, then the model cannot adapt since the CSP model cannot learn.
Links
Footnotes
-
Mahlau, Schubert, and Rosenhahn (2024) Mastering Zero-Shot Interactions in Cooperative and Competitive Simultaneous Games ↩
-
Barros and Sciutti (2023) All by Myself: Learning Individualized Competitive Behaviour with a Contrastive Reinforcement Learning optimization ↩