RIAL / DIAL
- 1 introduces Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL) to facilitate learning communication strategies in cooperative MARL settings.
- We assume a Dec-POMDP in the CTDE setting. In addition to environment action
, agents also have a communication action . - RIAL uses a DQN with a RNN for partial observability.
- Here, we use Independent Learning for action and communication selection. We use two networks for environment and communication actions respectively. This way, we do not need
model outputs. - For performance, we train the model with the following in mind:
- We disable experience replay since the environment is not stationary.
- To account for partial observability, feed the actions taken by each agent as inputs to the next time step.
- This can be extended to the Parameter Sharing case.
- Here, we use Independent Learning for action and communication selection. We use two networks for environment and communication actions respectively. This way, we do not need
- DIAL extends RIAL by allowing it to also be end-to-end trainable between agents by passing real-valued messages (gradients) to be shared between agents during centralized learning.
- Rationale: RIAL does not allow agents to give feedback on communication actions.
- During centralized learning, communication actions are replaced with direct connections between the output of one agent’s network and the input of another’s
- The C-Net network used here outputs two values — the
-values for environment actions and , the real-valued message to other agents that bypasses the action selector and is processed by the discretize/regularize unit. - During training, the DRU regularizes the output.
where
is noise added to the channel - During execution, the DRU discretizes the output.
- During training, the DRU regularizes the output.
- In DIAL, the gradient term for
is the backpropagated error from the recipient of the message.
- In DIAL, we find that the presence of noise forces messages to be made more distinct

- We assume a Dec-POMDP in the CTDE setting. In addition to environment action
Other
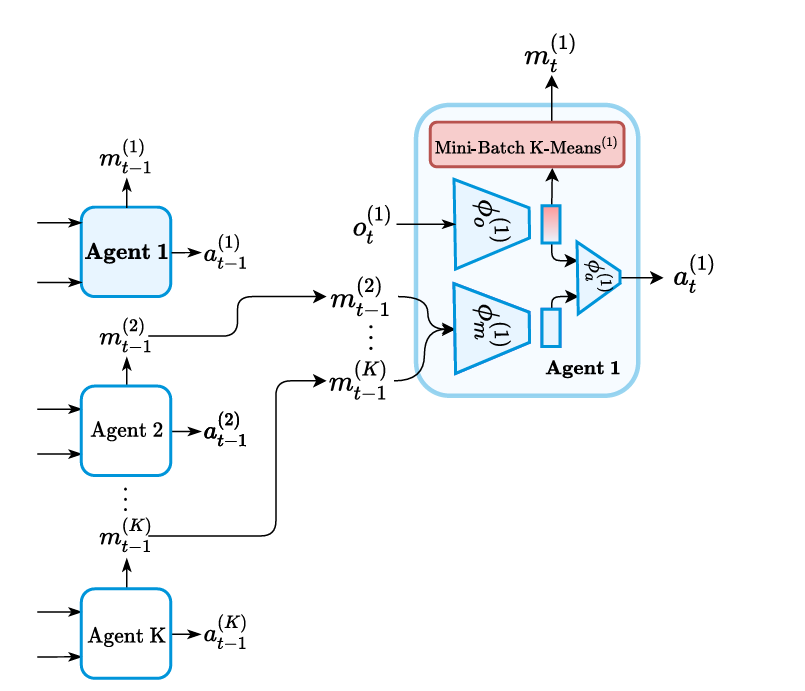
- 2 proposes ClusterComm, a fully decentralized MARL framework for communication in collaborative tasks.
- Discrete messages are created by clustering the output of the policy layer via
-means (more specifically, Lloyd’s algorithm). - It is based on how humans learned to communicate. Thus, it does not rely on parameter sharing or differentiable communication. All agents act independently and training is done fully decentralized.
- The rationale behind clustering is that it allows a compact representation of messages.
- All policies are based on the current observation and the messages
sent by all other agents. is an observation encoder that outputs a representation for . takes the concatenation of and produces a message representation. receives the concatenation of representation messages and the local observation too compute the action. - The output of
is discretized via Mini-batch K-means clustering.
- Discrete messages are created by clustering the output of the policy layer via
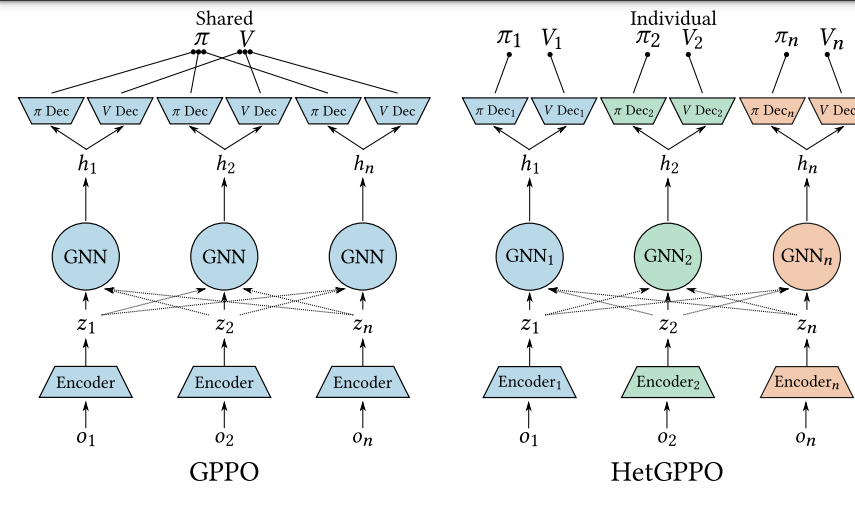
- 3 proposes a GNN based approach called Heterogeneous GNN PPO (HetGPPO) which enables both inter-agent communication and learning in Dec-POMDP environments.
-
Motivation: Prior methods address heterogeneity without considering the use of communication to mitigate the partial observability in a Dec-POMDP (i.e., CTDE relaxes this constraint for the critic during training). Relaxing the assumption to the case of homogeneous agents prevents agents from using heterogeneous actions to achieve their objectives.
-
We can extend the regular Game theoretic formulation by introducing a communication graph for each agent.
At each time step, the observation
is communicated to an agent in the neighborhood . The goal is still the same, however, to learn policies for each agent .
-
The model allows for behavioral typing — where environmental conditions nudge agents to behave in particular ways.
-
The proposed solution is both performant (compared to Homogeneous parameter sharing) and resilient (i.e., even with observation noise, the agents perform well.)
-
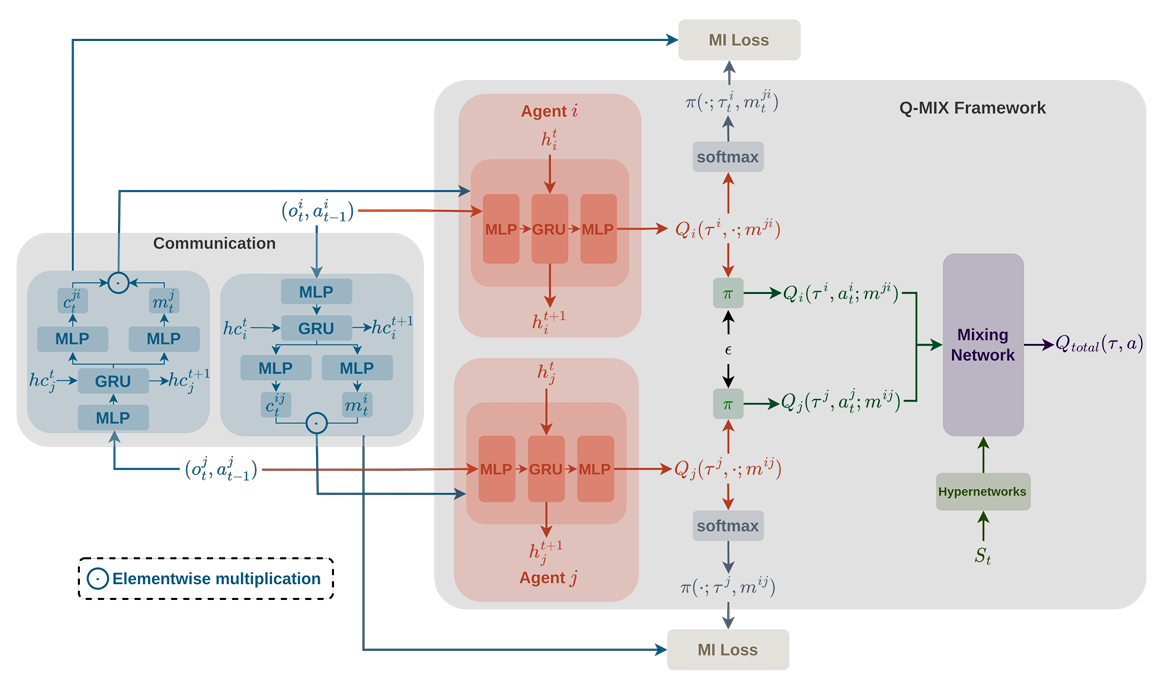
- 4 proposes a communication-based MARL framework for Traffic Signal Control. Agents learn what to communicate and to whom in a decentralized manner.
-
Agents learn to compress observations and action intentions into a message.
-
The proposed model called QRC-TSC improves upon DIAL by:
- Using variational inference to maximize mutual information between sent messages (and the communication action), and the recipient’s action.
- Introduce an entropy regularization term for communication policies to explore the communication action space.
- Make communication policies differentiable .
-
Let
and be sender and recipient respectively, the message and the corresponding communication action. generates a shared latent message distribution from which we sample . -
acts as a mask over messages during execution. It uses the Gumbel-Sigmoid approximation defined as follows. Let and the temperature parameter The objective to learn communication
is to maximize the mutual information between the sender’s message and the recipient’s policy given as The reward is then formulated as maximizing mutual information while encouraging exploration of policies provided as follows.
Let
be the replay memory, a joint local action-observation history and be the cross entropy. Messages are modeled as a joint distribution . Posterior estimates are also given by
-
- 5 examines communication learning in a mixed cooperative-competitive, partially-observable multi-agent setting where goals are shared between teams and are competitive across teams.
- Communication is done via a C-Net which takes in observations and outputs a vector message..
- An A-Net then uses the vector message and the observations in the environment to determine the next action.
- Communication is learnt via Differentiable Inter-Agent Learning
- Limitation: In scenarios where communication is shared across teams, performance will decline significantly
- Limitation: Not tested for cases with a large number of agents.
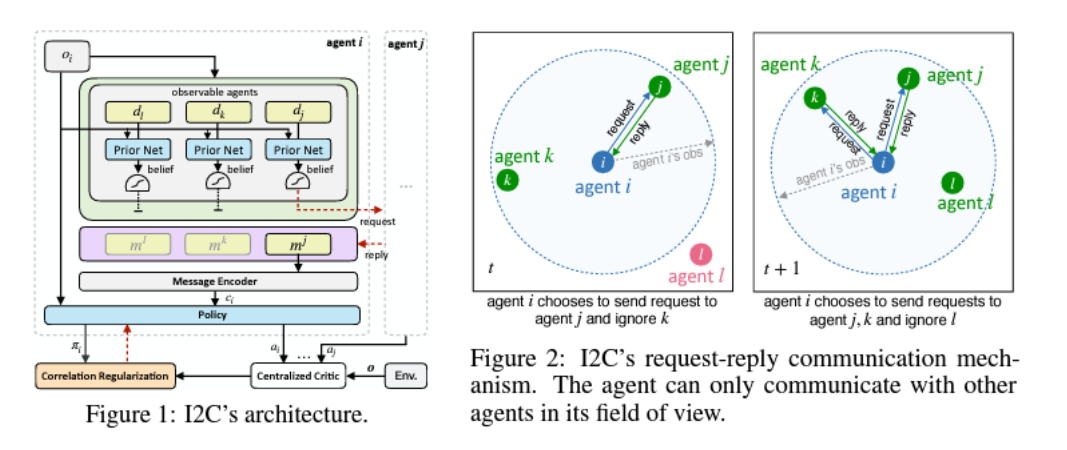
- 6 proposes Individually Inferred Communication (I2C) a MARL approach to learning a prior for agent-to-agent communication. The prior is learned via causal inference.
-
Each agent is capable of exploiting its learned prior knowledge to figure out which agent is relevant and influential by just local observation (i.e., it does not broadcast messages).
-
Communication works as follows. A prior network
takes and index information of agent . It outputs a belief on whether to communicate with . Agent
then sends a request to , which then responds with . All received messages for agent
are fed to the encoder to produce the encoded message . We learn the policy . -
Agents are more likely to communicate to agents which have more influence. The influence of agent
on is measured via the causal effect defined as follows Where
is the joint observation and is the joint action of all agents other than and . The respective distributions are then calculated as follows:
Where
is a temperature parameter. We also calculate
as a marginal distribution of -
The belief network learns the causal effect under the current state. More specifically, it learns using the dataset
during training. -
We also introduce correlation regularization to help the agent correlate other agent’s observation to the actions. This is done using the term
-
Accounting for communication gives the following gradient
The encoder network’s gradient is given by
-
Footnotes
-
Foerster, Assael, de Freitas, and Whiteson (2016) Learning to Communicate with Deep Multi-Agent Reinforcement Learning ↩
-
Muller et al. (2024) ClusterComm: Discrete Communication in Decentralized MARL using Internal Representation Clustering ↩
-
Bettini, Shankar, and Prorok (2023) Heterogeneous Multi-Robot Reinforcement Learning ↩
-
Bokade, Jin, Amato (2023) Multi-Agent Reinforcement Learning Based on Representational Communication for Large-Scale Traffic Signal Control ↩
-
Vaneste et al. (2021) Mixed Cooperative-Competitive Communication Using Multi-Agent Reinforcement Learning ↩
-
Ding, Huang, Lu (2020) Learning Individually Inferred Communication for Multi-Agent Cooperation ↩