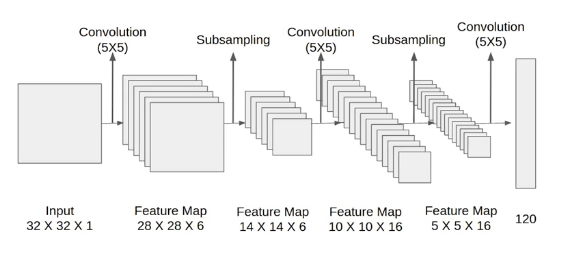
LeNet-5
- Made for the task of classifying hand-written digits. It was one of the earliest CNNs
- It consists of two blocks — a convolutional block and a dense block.
- In each convolutional block, we use a sigmoid activation function and subsequent average pooling operation.
- After the convolutional block, we flatten the input through one last convolution to feed it into the dense block in order to use the extracted feature maps as input.
- Model complexity is controlled via weight decay
- It defined the use of convolutional layers, however it was not widely adopted due to a lack of hardware.
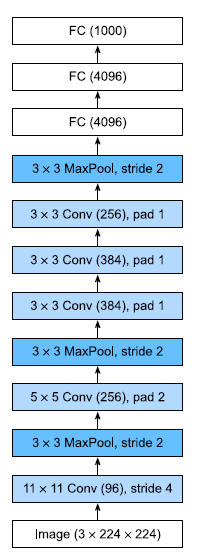
AlexNet
- An improved version of LeNet-5 that was made to run on GPUs. Parallelization greatly improved the performance.
- Made use of modernized techniques such as Image Augmentation, Dropout, and the use of ReLU instead of the sigmoid as its activation function.
- The use of ReLU means that training is easier and is less prone to the vanishing gradient.
- Dropout controls the model complexity.
- For parallelization, we use grouped convolutions
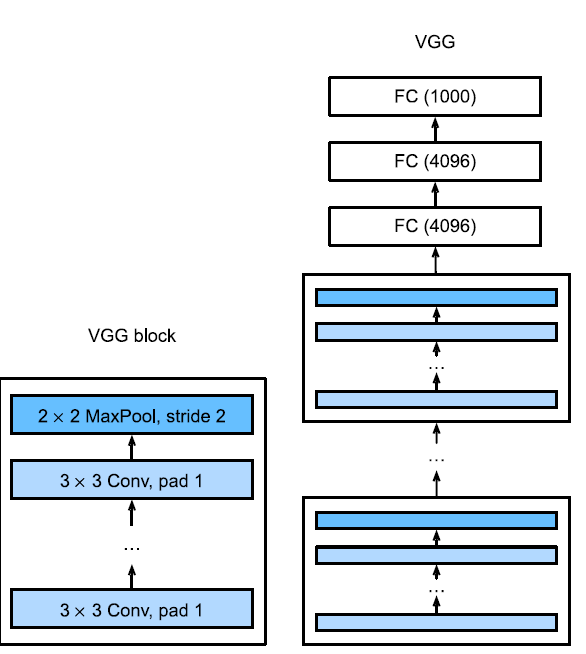
VGG Network
- Made use of convolutional blocks which perform a series of convolutions before any pooling is done.
- The resulting network has the same number of parameters as a dense network with a wider convolutional kernel. However, the performance is much better.
- The convolution layers were kept small to support a narrow yet deep network.
- The resulting network has the same parameters as that of a dense network with a wider convolutional kernel, however, the performance is much better.
Network In Networks
-
Aimed to address the fact that CNNs with too many parameters can slow down layers.
-
It also aimed to add more fully connected layers at the end of the network to introduce non-linearities without destroying the spatial structure of the network.
-
For low resolution images, the Global Average Pooling operation introduced more translational invariance.
-
It made use of 1x1 Convolutional layers to minimize the number of parameters without sacrificing accuracy by convolving over the channels of the image rather than compress it.
-
Each NiN block is multi-channel with an output equal to the number of classes.
-
After each NiN block is a Max Pooling operation. We forego the use of fully connected layers by instead having a Global Average Pooling operation.
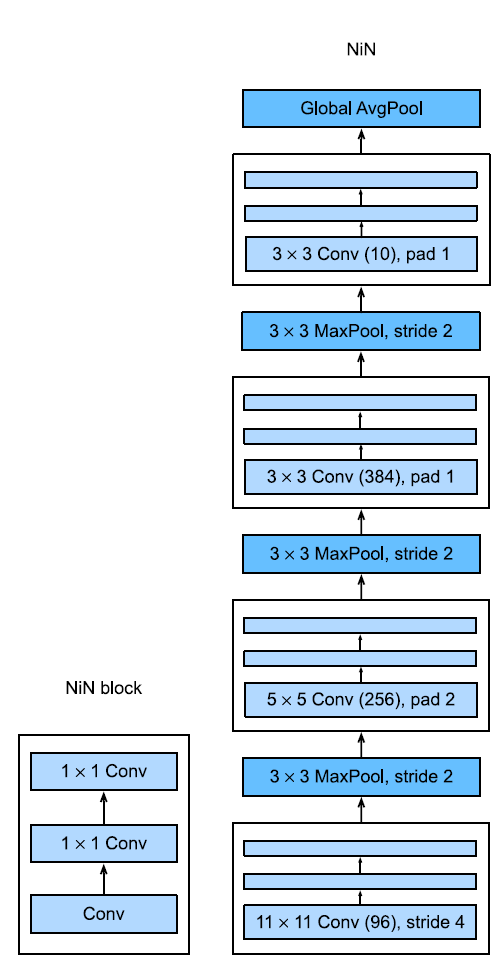
- In this case, the NiN block comprises of 1x1 convolutional blocks which can be thought of as a Fully Connected Layer acting independently on each pixel location.
GoogLeNet
- Strengthens Network in Networks by allowing for multiple granularities of feature maps extracted.
- It is cheaper while having more improved accuracy.
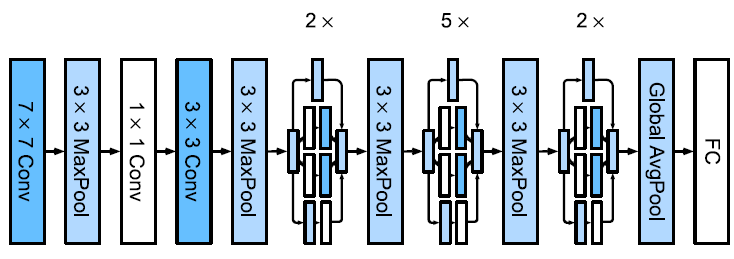
- This is done through the use of Inception Blocks that have many parallel branches that all perform convolutions but with different kernel sizes to scan at varying levels of detail.
- The first three branches aim to extract information at different spatial sizes.
- The middle two branches also add a 1x1 convolutional layer to reduce the number of channels and reduce model complexity (similar to Network In Networks).
- The fourth branch uses a max pooling layer followed by another 1x1 Convolutional layer to change the number of channels.
- All branches yield the same dimension of input and output and their outputs are concatenated along the channel dimension. This is the block’s output.
- This is performant since we can scan the input at varying levels of detail.
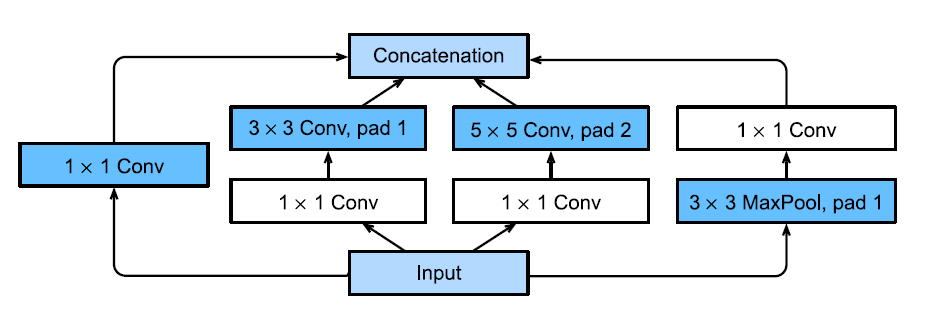
ResNet
-
Aimed to increase expressivity of its predecssors and allow it to precisely capture a particular class of functions through increased complexity
-
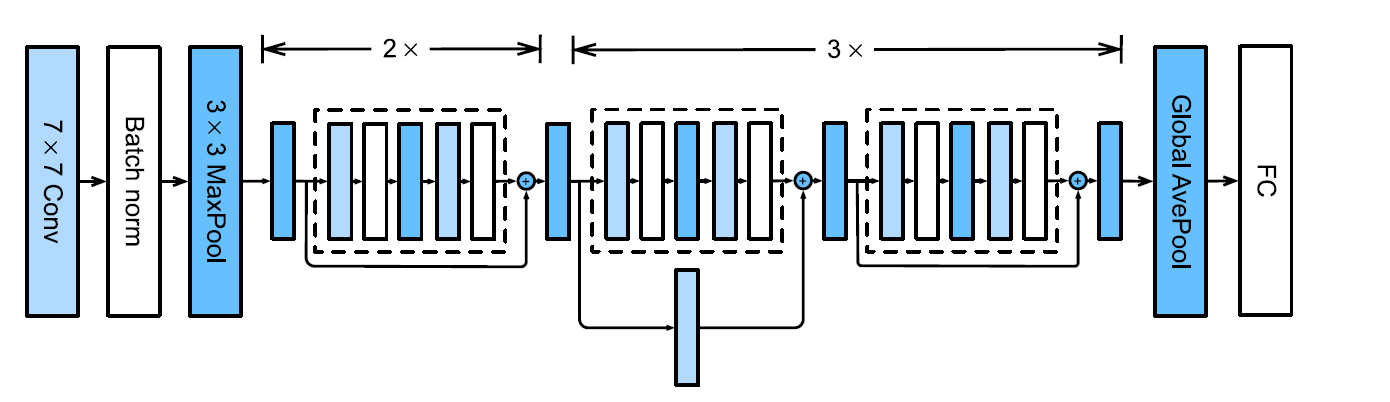
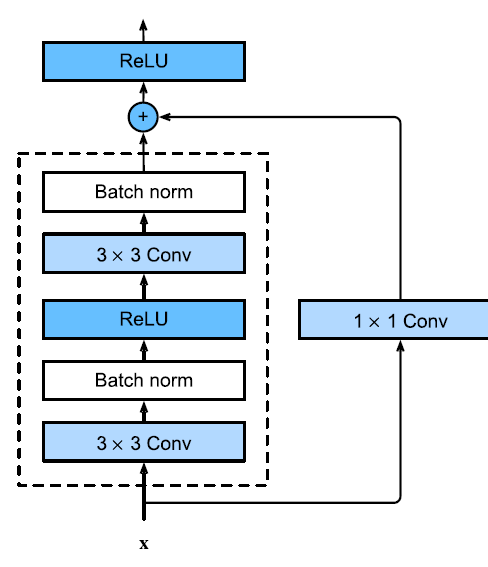
To that end, introduced skip connections or residual blocks whcih connected the current output with the output of the previous layer (before any activations).
-
By using skip connections, the model counteracts performance degradation due to the deeper architecture, as well as the vanishing and exploding gradient problems.
-
It introduces an inductive bias that the target function is close to the identity function. This is achieved through ResNet Blocks — a type of residual block.
-
Architecturally, it begins similarly as GoogLeNet. After each Convolutional layer we add a Batch Normalization layer. We then stack four ResNet blocks and then a Global Average pooling layer + a Fully Connected Layer
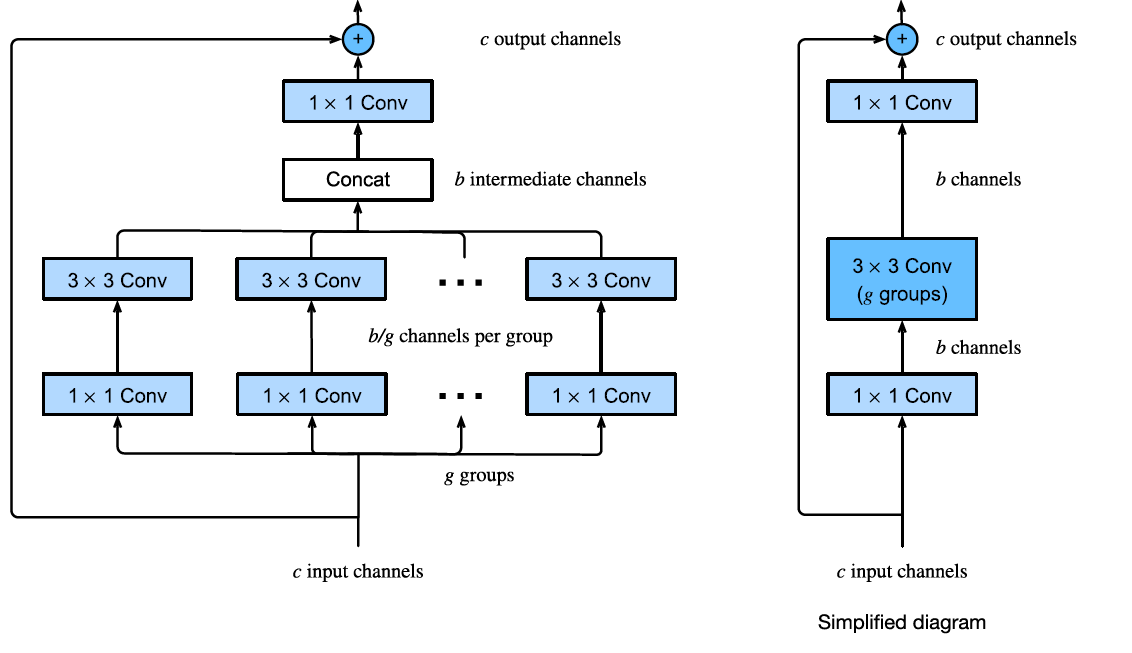
DenseNet
-
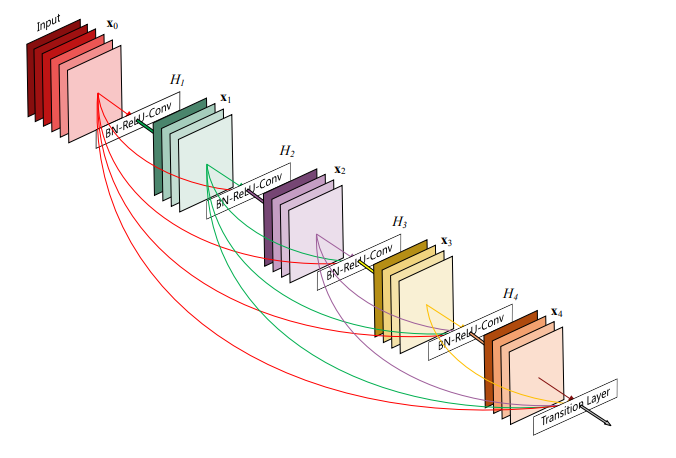
A generalization of ResNet which has each layer be skip connected to all previous layers. These are called dense connections
- It is more expressive as it incorporates previous feature maps from earlier on in the network.
- It is also more computationally expensive and more complicated to parallelize.
- Compared to ResNet, the model parameters are relatively smaller. It introduces a form of regularization and allows for fewer parameters overall since feature maps are not lost.
- The network can also be much narrower since the feature maps are preserved.
-
Dense Blocks 1 consist of multiple convolutional blocks with the same number of output channels. Each convolutional block follows a sequence of Batch Normalization, ReLU and Convolutional Layer
Notably, each layer within the block is connected to all previous layers. If we notate
as the output of the current layer, and as our activation function. Then Wherein we concatenate the feature maps from the previous layers.
-
A transition layer in the context of DenseNet is used to control the complexity of the model using a 1x1 convolutional layer as well as an average pooling layer to trim the size of feature maps by half.
-
The model itself uses the same single convolutional layer and max pooling layer. Then, four dense blocks and finally a Global Average Pooling layer and a Fully Connected layer.
DenseNet-B
- An extension of the DenseNet model where we introduce a bottleneck layer by replacing the Batch Normalization-ReLU-Convolutional layout of a Dense Block into
- We introduce a 1x1 convolutional layer in between each layer to reduce the number of input feature maps and improve computational efficiency.
DenseNet-BC
- An extension of DenseNet-B where we also compress the transition layers of the model to reduce the number of feature maps.
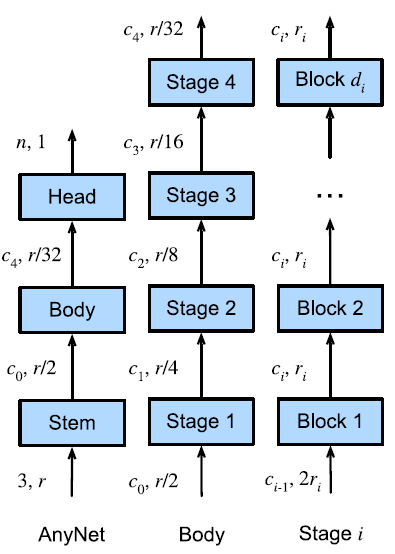
AnyNet Design Space
- A generalization of the CNN architecture based on the observation that most modern neural networks follow the same structure.
- A stem performs image pre-processing techniques (i.e., using a convolutional layer with a large window size).
- A body consisting of convolutional blocks carry out transformations to go from images to feature maps. It operates on the image in decreasing resolutions
- A head consists of an interface that can convert the outputs of the body into the desired outputs for the task.
- It operates under the following assumptions:
- General Design Principles actually exist and these principles indicate good performance.
- Partial Metrics are sufficient We need not train the network to convergence to assess whether it is good. Approximations are enough.
- Small networks usually scale. Results obtained at a smaller scale can generalize to larger ones. Only after we have found a good architecture do we test if it scales well.
- Optimization is moderately easy. Aspects of the design can be approximately factorized such that it is possible to infer their effect on the quantity at the outcome somewhat independently.
Links
-
Zhang et. al Ch. 7.6, Ch. 8 - for a more in depth view on all the models discussed so far.
Footnotes
-
Huang et al. (2018) Densely Connected Convolutional Networks ↩