-
The toxicology hypothesis — Vomiting while motion sick can be traced back to the same sensors for motion sickness being associated with detecting if we are poisoned (since this also causes nausea). Hence, the response is to throw up the poisoned food.
- Rotten potatoes can produce a lethal gas called Solanine
-
Chinese Ghost Marriages are marriages in which one or both parties are deceased.
- People have exploited this practice for profit due to cultural beliefs about having children that are married.
- Said exploiters perform grave robbery or murder women to then sell — “Fresh Ones” are those recently deceased or about to die; “Wet bodies” are those who have died within a few weeks and “Dried Meat” who have died longer.
-
Caskets can fail and when they do they leak blood and embalming fluid
-
The Dragon Paradox - If Dragon’s aren’t real, then why do many cultures from around the world allude to dragons.
-
S Risks — Fate’s Worse than extinction - S risks pertain to events that have astronomically high scope and high severity. They typically share common elements
- (1) they involve many more beings than currently exist;
- (2) are brought about by significant technological advancements;
- (3) involve suffering due to a part of a larger process; and
- (4) are preventable with foresight
-
Functional Fixedness can be overcome as follows:
- Uncommitting - abstract the problem down to its essential components.
- Draw inspiration from other places.
- Draw opinions from other fields
-
Our right and left hemispheres of the brain experience consciousness differently. Splitting them apart leads to some weird behaviors. Dissecting the brain reveals that the most predominant aspect of it is involved in justifying and rationalizing our decisions and experiences, even if it is done so incorrectly or irrationally.
-
Tautomers are structural isomers of chemical compounds that readily interconvert. That is, through a process called tautomerization, one can convert one into the other and vice versa.
-
In Japan, bowing is a sign of respect. The deeper / longer the bow, the more formal and respectful.
-
Japanese people avoid physical contact.
-
Meishi - business cards exchanged when meeting someone in a business situation for the first time.
-
Japanese give their names family name first and given name last. They do not have middle names.
-
Poludnitsa - A mythical figure in Slavic mythology associated with heat stroke.
-
The Ghost of Kyiv - a flying ace who shot down six Russian planes during the Kyiv offensive
-
Odesa Catacombs - a vast network of catacombs in Ukraine. It is easy to get lost in these catacombs.
-
The Strid - A portion of the River Wharfe in England. While it looks like an ordinary stream of water on the surface, underneath it consists of a network of sedimentary rock that can rip a human to shreds.
-
Gout was also called the “Disease of Kings”
-
The same neural clusters that are used in sensory perception are used in conceptual imagining.
-
Storytelling is really what the brain does. We experience the world as a sequence of events that flow, generally, from one to the next over time. When we try to communicate with others and with ourselves, we actually construct stories
-
RAMBO Attack - an attack involving writing to RAM and picking up on the EM signals emitted.
-
Jerusalem Syndrome - a psychological phenomenon associated with tourists visiting Jerusalem.
-
The Ignoble Prize (2024). All of these are based on one paper. Skepticism allowed but these are silly facts nonetheless.
- Beards most likely evolved as a mechanism to protect the jaw. Hence, why they only grow on a specific part of the face.
- You can control impulsive behavior by controlling your urge to pee.
- You can relieve an itch by having an image of scratching a non-itchy area.
- You can train people with dog clickers effectively (via operant conditioning)
- Orgasms can help decongest a clogged nose.
- There are 100 hairs per nostril regardless of sex and race.
- The left scrotum tends to be warmer than the right.
- There is a correlation between finding a romantic interest and synchronized heart rates
- There is a correlation between narcissism and having distinct eyebrows.
- There is a memetic effect induced by looking at a window which attracts a crowd to look at the same window. The contagiousness is dependent on whether the person looking stops what they are doing.
-
The Toulmin Model is a framework for understanding arguments. An argument is broken down into six parts. Every argument has a claim, the grounds, and a warrant.
- The claim is the main argument.
- The grounds are the evidence and facts that support the claim.
- The warrant is the assumption that links the grounds to the claim.
- The backing refers to any additional support of the warrant.
- The qualifier shows that a claim may not be true in all circumstances (i.e., using “some” or “maybe”).
- The rebuttal is an acknowledgment of another valid view of the situation.
-
Irrationality can sometimes be rational.
- Pure unconditional aggression and pure unconditional capitulation are destined to fail as strategies of social exchange in a society of multiple interaction and mutual dependence.
- Neither unqualified cooperation nor unqualified competition may be regarded as evolutionarily stable. Both may be trumped by invading or mutating counterstrategies
- Altruism, though undoubtedly an ingredient of basic group cohesion, is perfectly capable of arising not out of some higher-order differential such as the good of the species or even the good of the tribe, but out of a survival differential existing purely between individuals.
-
(W. Somerset Maugham in “Of Human Bondage” ): “Man performs actions because they are good for him, and when they are good for other people as well they are thought virtuous … It is for your private pleasure that you give twopence to a beggar as much as it is for my private pleasure that I drink another whiskey and soda. I, less of a humbug than you, neither applaud myself for my pleasure nor demand your admiration.”
-
Encephalitis Lethargica - a neuropathological disease that caused people to become lethargic to the point of being human statues
-
The Law of Jante from Scandinavia. It’s a social attitude towards expressions of individuality. The key rule is You are not to think you’re anyone special or that you’re better than us
- You are not to think you are anything special
- You are not to think you are as good as we are.
- You are not to think you are smarter than we are.
- You are not to imagine yourself better than we are.
- You are not to think you know more than we do.
- You are not to think you are more important than we are.
- You are not to think you are good at anything.
- You are not to laugh at us.
- You are not to think anyone cares about you.
- You are not to think you can teach us anything.
Research Papers
- 1 discusses limitations for generic learning algorithms for pursuing adversarial goals in competitive environments
-
Let
be playing programs for a particular game. Define a Computational Algorithm . such that We treat
itself as characterizing a game. We also assume that each playing program runs within a time limit, and the game only has a finite state. Thus, the set of possible playing programs is large but finite.
-
Consider the Normal Form representation of the game given by the matrix whose entries are
. Each program then represents a strategy. -
We can perform the analysis using a Turing Machine. One particular case to consider is when learning is allowed called open source competition . That is Player
can learn Player ’s strategy and vice versa via information exchange. We do this as follows. Let
be a universal Turing machine with header applied to input and produces output . The learning algorithms can be defined as An algorithm
wins over either by producing where or by producing and the competing algorithm does not halt (i.e., winning requires the program to halt.) ’ is a universal winner for game when it can defeat every opposing algorithm . -
(1Thm. 1): Any algorithm competing in an open source competition associated with any strongly intransitive game cannot be a universal winner.
In fact (1 Thm 3) provides the stronger statement: Any algorithm competing in an open source competition cannot be a universal winner.
-
Proof: For Thm 1. A hypothetical universal winner
halts so that . However, by strong intransitivity, take the program that runs first and then obtains which is guaranteed to exist. For Thm. 3, we can show that
cannot implement a universal halting function so it cannot determine whether halts given data . Hence that ignores and executes is not defeated by . Hence, is not a universal winner.
-
-
Thus, there is a new strategy: Refuse to halt while hiding any intention to halt.
-
This also implies No learned algorithm can always win and Intransitivity adds complexity.
-
- 2 employs competitive learning for modeling physical systems.
- In particular, each model in the agent system makes predictions in localized regimes within the dataset. This allows models to specialize on their own niche within the problem space. The models are extracted from the dataset.
- This is done by introducing a new loss function that weighs each sample. Let
be the weight of the -th observation for the -th model. Then - The weights are calculated as follows
Where
is the squared error of the best model for an observation Anddetermines the degree of separation between models (higher = more distinct). - In this scheme, if a model performs better than others for an observation, that observation is assigned a weight of
to that model alone and to to the others. Models influence the loss landscape itself, carving out their own niches - In practice, we use a smoothed version of the weight parameter computed by averaging the weights of its
nearest neighbors. In particular in place of we use Where for a particular sampleis its closest neighbors. - Limitation: We need too determine
, the number of models to employ. - Limitation: Convergence to local minima.
-
3 introduces Bayesian Theory of Mind on Policy (Bayes-ToMoP) which dynamically detects the strategy of an opponent. In particular, it detects unseen strategies and learns a best response.
-
It addresses the drawbacks of ToM approaches — that they are designed only for primitive strategies; and it does not adapt to unseen strategies.
-
It also addresses the drawbacks of Bayesian Policy Reuse — that they are designed for simple opponents with stationary strategies.
-
Bayes-ToMoP is a recursive algorithm. At order
, we assume a zero-order belief about the opponent’s strategies, denoted for the belief that the opponent adopts strategy . Given utility
, We also have a performance model which describes the probability of using a policy against . At order
, the belief that the opponent believes the agent will choose policy . We incorporate as well as a correction term to weigh in first-order prediction . This integration function is given as follows where is a weighting term. The first-order belief is then updated based on Bayes’ Rule (see Lines 6 - 11) below.
-
To update the first-order confidence
. The idea is to use game outcomes as a signal to determine if previous predictions are correct and adjust the first-order confidence according. The rule is given below. Let be defined as the win-rate We also let
be the adjustment rate, and a threshold parameter. Here
is an indicator function to control the direction of adjusting . Its value is adjusted based on its previous value
0 & (v_i\le \delta \wedge F’(v_i)= 1) \end{cases} $$
-
We also allow for detecting strategies. Consider the win rate
over the most recent episodes ( is a hyperparameter). The lowest win rate among the best-response policies can be seen as the upper bound for
. If is the win-rate against policy , then If the win rate of a policy is lower than
, then that means all existing policies show poor performance against the current strategy. When we detect a new strategy, we learn a new policy against it.
-
(3 Thm 1 ) The strategy detection described is optimal.
-

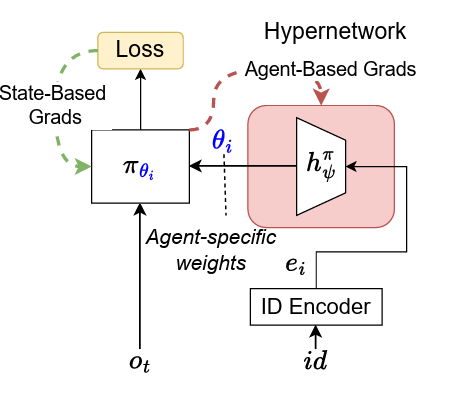
- 4 introduces HyperMARL which uses hypernetworks to balance between Full Parameter Sharing (efficiency) and Independent Learning (specialization).
-
A specialized environment is one where
- The optimal joint policy
consists of two distinct agent policies. - Any permutation of the policies in
results an expected return that is weakly lower or equivalent to the original.
- The optimal joint policy
-
A joint policy is diverse based on the System Neural Diversity defined as
Where
is a distance function (in this case, the Jensen-Shannon Divergence). -
The hypernetwork
takes context vector and outputs the weights for both the policy and critical networks. That is The policy gradient is given with respect to the hypernetwork parameters
. We can decouple the two gradients during training. Where
is the advantage - The context vectors are learned embeddings for each agent.
-
HyperMARL scales efficiently, is robust against variations in architecture, initialization, and conditioning, and maintains performance compared to the two extreme methods.
-
Limitations: Uses naive implementation of hypernetworks and can be further optimized.
-
Partials
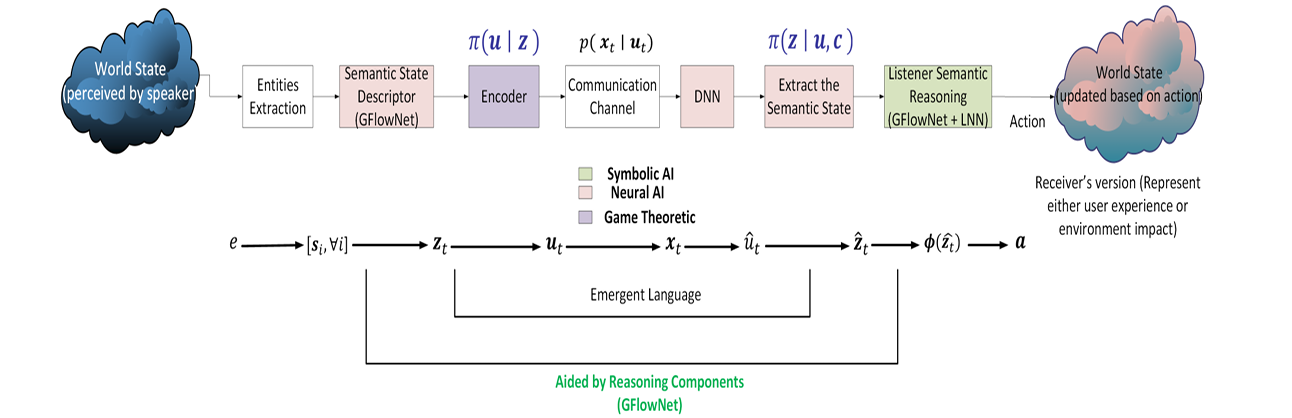
- 5 proposes an emergent semantic communication (ESC) framework consisting of a Signaling game for emergent language design and a neuro-symbolic AI approach for causal reasoning.
-
The emergent language learns to transmit and receive signaling strategies in a compositional manner (i.e., combining simpler concepts to describe richer concepts), while being semantically aware.
Composition means the language is generalizable. Semantic awareness means the language is data efficient (more information with less bits).
-
The proposed ESC framework is formulated as follows.
A speaker observes a sequence of events
from the environment and intends to send a causal description about the event to a listener. The listener completes a set of sequential tasks drawn from probability distribution
. From the inferred semantics, the listener executes an action represented by distribution
, where and represents the listener’s semantics (i.e., the set of logical conclusions the listener is evaluating). The semantic effectiveness pertains to the effectiveness of the actions on the listener’s environment.
The speaker itself is unaware of the listener’s intentions and its logical interpretations of the received semantics.
The speaker can extract entities — features from
represented as the vector and . -
To infer hidden relations between entities, we use a semantic state descriptor which outputs a description, defined as the sequence of entities and their relations
where denotes the relation between and . In particular We use the Structural Causal Model (SCM) framework considers observables which are vertices in a directed acyclic graph. Each observable is defined
as Where
are the parents of in the graph, and is a random -vector. The causal DAG is learned via the posterior distribution The above is learned via a Generative Flow Network. We can also add interventions (indexed via
) on the DAG to form the posterior Using reconstructed state description
, we form logical formulas evaluated by computing , where the logical formula is defined as Which fuzzily evaluates to a real number in
. Each is also a probability value. -
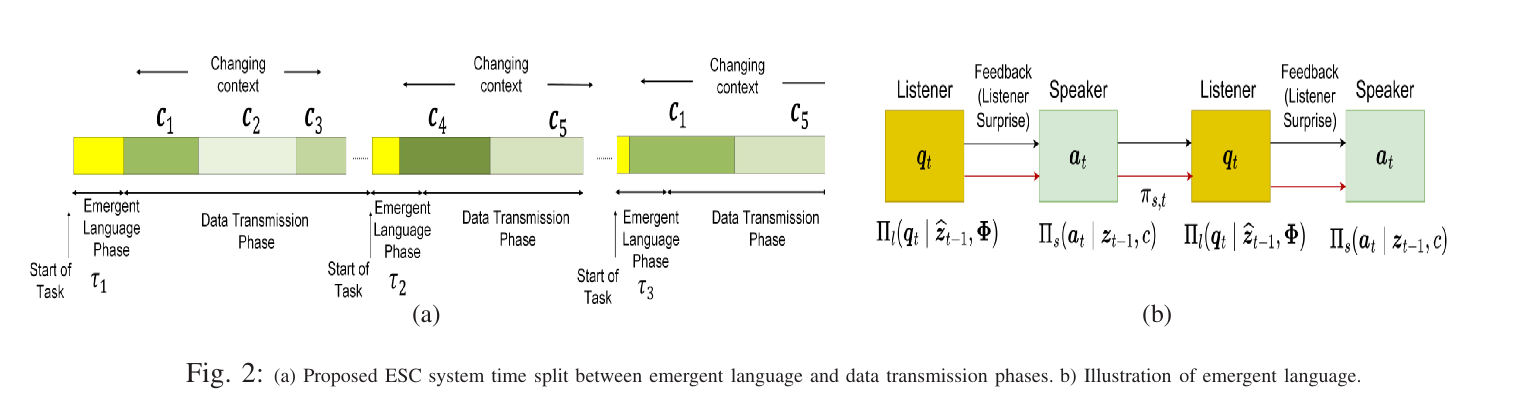
To learn the semantics (that is, mapping from syntactic
to vocabulary space), we use the Emergent Language Game — a two player contextual signaling game where the goal is to learn the speaker transmit distribution and the listener inference distribution where is the context capturing syntactic space. If the set of all distributions for and are denoted respectively, then the signaling game is defined by the tuple -
Learning is done via a question and answer system. A question only involves on entity and the answer is either an entity or a Boolean variable.
Each answer represents a simpler state description within context
and corresponds to task . -
Assume:
is known to both speaker and listener. However, the listener is unaware of the event dynamics generating . -
Assume: Only the listener is aware of the semantics stemming from any state
. -
In communication round
, the speaker has state Where
are questions and answers respectively. The listener has state
Where
represents the inference about at time -
Questions are sampled based on the stochastic policy
and similarly, Answers are evaluated using . Only questions are predetermined. Answers depend on the sampled context. Both policies are known.
-
-
To measure Semantic Information, we use a category theory based measure.
-
Any entity form objects in the syntax category
. Morphisms from to in are formed when expression extends from expression . Morphism
is represented using a probability distribution . -
The semantic information conveyed by any expression
is given by Such that the support of
is defined by the representable copresheaves .
-
-
Bottom
Unstructured exploration goes here
Footnotes
-
Kimenko, and Kimenko (2020) On Limitations of Learning Algorithms in Competitive Environments ↩ ↩2 ↩3
-
Ukorigho and Owoyele (2023) A Competitive Learning Approach for Specialized Models: A Solution for Complex Physical Systems with Distinct Functional Regimes ↩
-
Yang et al. (2018) Towards Efficient Detection and Optimal Response against Sophisticated Opponents ↩ ↩2
-
Tessera, Rahman and Albrecht (2024) HyperMARL: Adaptive Hypernetworks for Multi-Agent RL ↩
-
Thomas and Saad (2022) Neuro-Symbolic Causal Reasoning Meets Signaling Game for Emergent Semantic Communications ↩