-
Data Analytics pertains to the processing of data to infer patterns, correlations or models for prediction. It may involve generating aggregate data and reports from a data warehouse.
- Descriptive - what happened in the past?.
- Diagnostic - why something happened in the past? Typically through the use of drill down analysis
- Predictive - what can happen in the future?. Typically using Machine Learning.
- Prescriptive - what we should do in the future.
-
Online Analytic Processing is a technology that performs multidimensional analysis at high speeds on large volumes of data from a data warehouse for the purposes of gathering new insights from the databases of a business through complex queries.
-
Online Transaction Processing is a technology that enables the real-time execution of large numbers of database transactions by large numbers of people, typically with the intent of modifying data.
- We usually use operational databases for OLTP
- OLTP systems typically possess only simple transactions that enable multi-user access while maintaining data integrity. The processing should, therefore, be fast to handle the expected large amount of queries.
Data Warehouses
-
A Data Warehouse is a central repository of information that can be analyzed to make more informed decisions.
- It contains data from multiple operational databases of the enterprise.
- An operational database is a database that is used for the day-to-day processes of the business.
- Typically it supports modification of the data in real time by providing Transactional Database as the main abstraction to guarantee data consistency.
- It is subject oriented - obtained to answer a particular business question
- It uses integrated data - data that are collected from disparate sources and placed in a warehouse in a consistent format
- The data are time-variant, The data can change over time
- The data are non-volatile. It typically does not change. It is historic data.
- The data is multidimensionality
- It contains data from multiple operational databases of the enterprise.
-
Some considerations
- Acquisition of the data of the warehouse should be
- From multiple heterogeneous sources
- Formatted for consistency
- Cleaned for validity
- Fitted into the data model of the warehouse
- Loaded into the warehouse
- Data storage should meet the query requirements efficiently
- Gives full consideration to the environment in which the data resides
- Should support ad-hoc querying.
- Acquisition of the data of the warehouse should be
The Dimensional Model
- A dimensional data model is a Data structure technique that aims to organize data via fact tables and dimension tables in a star or snowflake schema in such a way that data retrieval can be optimized for OLAP.
- It allows for high performance access.
Dimension Table
-
A dimension represents a single set of objects or events in the real world.
- The dimensions are the qualifiers that make the measures found in the fact table meaningful as they give context.
- Each dimension may be organized into some form of conceptual hierarchy based on its attributes or its elements. It is tied to the granularity of the fact table.
- The lowest level of detail that is required for data analysis determines the lowest level in the hierarchy.
- Levels higher than this base level store redundant data. The redundancy is in place to reduce the number of joins required to make a query.
-
Each dimension is implemented as a dimension table. They contain tuples of dimension attributes that describe reference data.
- The attributes of the dimension table act as constraints of the data warehouse.
- The tuples in the table are uniquely defined by (have a primary key) a single surrogate key which are used for joining fields between the fact and the dimension table. This has the following advantages:
- More efficient joins because we only use a single field.
- Buffering from operational key management practices, preventing situations where removed data rows might reappear when their natural keys get reused or reassigned after dormancy.
- Mapping to integrate disparate sources.
- Handling unknown connections
- Tracking changes in dimension attribute values
- Simple, Shorter, and consistently formatted for all keys.
- Allows data in the warehouse to have some independence from the data as it is modified.
-
A dimension attribute is a column in a table that represents a level of summary within a dimension hierarchy. They are typically more or less constant. We want them to be
- Verbose
- Descriptive
- Complete
- Discretely valued
- Quality assured
-
A dimension element pertains to another dimension that exists at a lower level than another dimension.
- This introduces a hierarchical structure of related elements that allow users to access data at different levels of detail.
Fact Table
-
The fact table shores facts about the business and points to the key value at the lowest level of each dimension table.
- We should consider the granularity of the fact table.
- This pertains to how we define an individual individual low-level record in a fact table.
- It is desirable to have a finer level of detail since it is easier to generalize than to decompose.
- Fact tables typically have two classes of columns, those that are foreign keys to dimensional tables, and those that contain actual facts.
- We should consider the granularity of the fact table.
-
Facts pertain to the quantitative, factual measure of the business about a subject. Facts are unlikely to change because they are historic.
Schemas
- A Star Schema is a logical structure that has the Fact Table at its center surrounded by denormalized Dimension Table The denormalized structure supports faster retrieval operations at the cost of poorer modification operations.
- A snowflake schema is a variant of the star schema wherein some of the dimension tables are normalized to form a hierarchy.
- Dimensions contain subdimensions.
ETL and Data Integration
-
Data Integration - the process of consolidating data from multiple disparate sources together to provide users with a unified view.
-
ETL is a data integration process that combines data from multiple sources into a single, consistent data storage
- Extract - During data extraction, raw data is copied or exported from source locations to a staging area. Data management teams can extract data from a variety of data sources, which can be structured or unstructured.
- Transform - In the staging area from extraction, the data undergo data processing. The data are transformed and consolidated for its intended analytical use case. This involves
- Data Cleaning operations such as cleansing, de-duplicating and authenticating.
- Performing calculations, translations or summarizations based on the raw data.
- Conducting audits to ensure data quality and compliance.
- Removing, encrypting or protecting data governed by industry or governmental regulators.
- Formatting data to tables or joined tables for the data warehouse (i.e., creation of surrogate keys)
- Load - the data are moved from the staging area to the data warehouse. This is followed by loading of incremental data changes. It is also here where we may activate additional constraints on the data.
OLAP
- A OLAP Cube - a Multidimensional representation of data. Each axis in the cube is a dimension and each entry in the cube represents a fact.
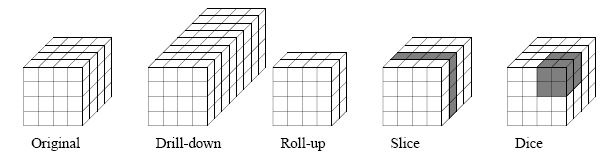
- A Drill Down operation allows a user to zoom in on the OLAP Cube, navigating from less detailed records to more detailed data. This involves stepping down in the dimensional hierarchy or adding additional dimensions.
- A Roll Up operation performs aggregation on the OLAP cube by climbing down the dimensional hierarchy or by reducing the dimensions. It lets the analyst zoom out and get a summarized overview of the data.
- A Slice operation is a subset of the cubes that correspond to a single value for one or more members of a dimension.
- A Dice operation describes a smaller cube within the original cube that is obtained by selecting two or more dimensions
- A Pivot is an operation on the OLAP cube that provides an alternative view of the data by transposing the dimensions